Created
Sep 21, 2021 05:49 PM
Topics
ValidationFormulaChoosing Validation Set Size Fold-Back-In Validation Procedure: Make Most Use of DataModel SelectionCross ValidationLeave One Out AnalysisPros & ConsModel Selection with Cross ValidationBayesian Decision TheoryBayes RuleGivenTo Find: Posterior ProbabilityErrorConditional RiskBayes TheoremEvidenceConditional RiskBayes Decision RuleFrequentist vs Bayesian ApproachBayesian Parameter EstimationExample: Logistic RegressionHow to Choose a Prior?? LearningNaive Bayes ClassifierDiscriminative vs Generative Model
Validation
For any hypothesis
- Overfitting Penalty: estimated by regularization
- : estimated by validation
Formula
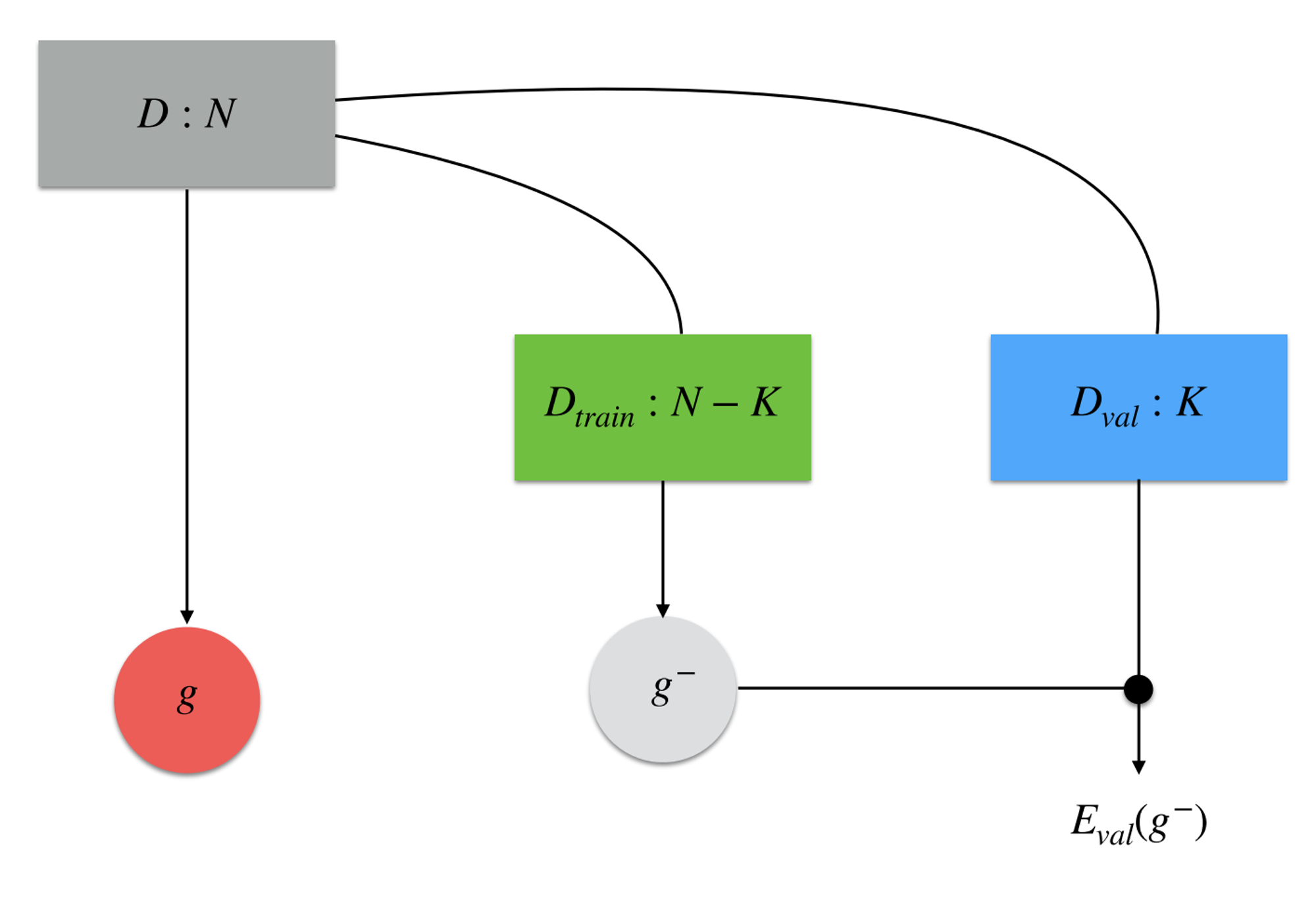
Dataset
- Training set samples
- Validation set samples
the hypothesis selected after training on
Expected value of validation error
This is because
Thus we have
- Expected value of validation error closely matches
Choosing Validation Set Size
⬆️ ⇒ ⬇️


too large ⇒ training set size too small
Practical Rule: use 20% of as
Fold-Back-In Validation

Procedure: Make Most Use of Data
- Separate the training & validation set
- Tune model to find best hyper-parameters
- Put validation set back to train the last time
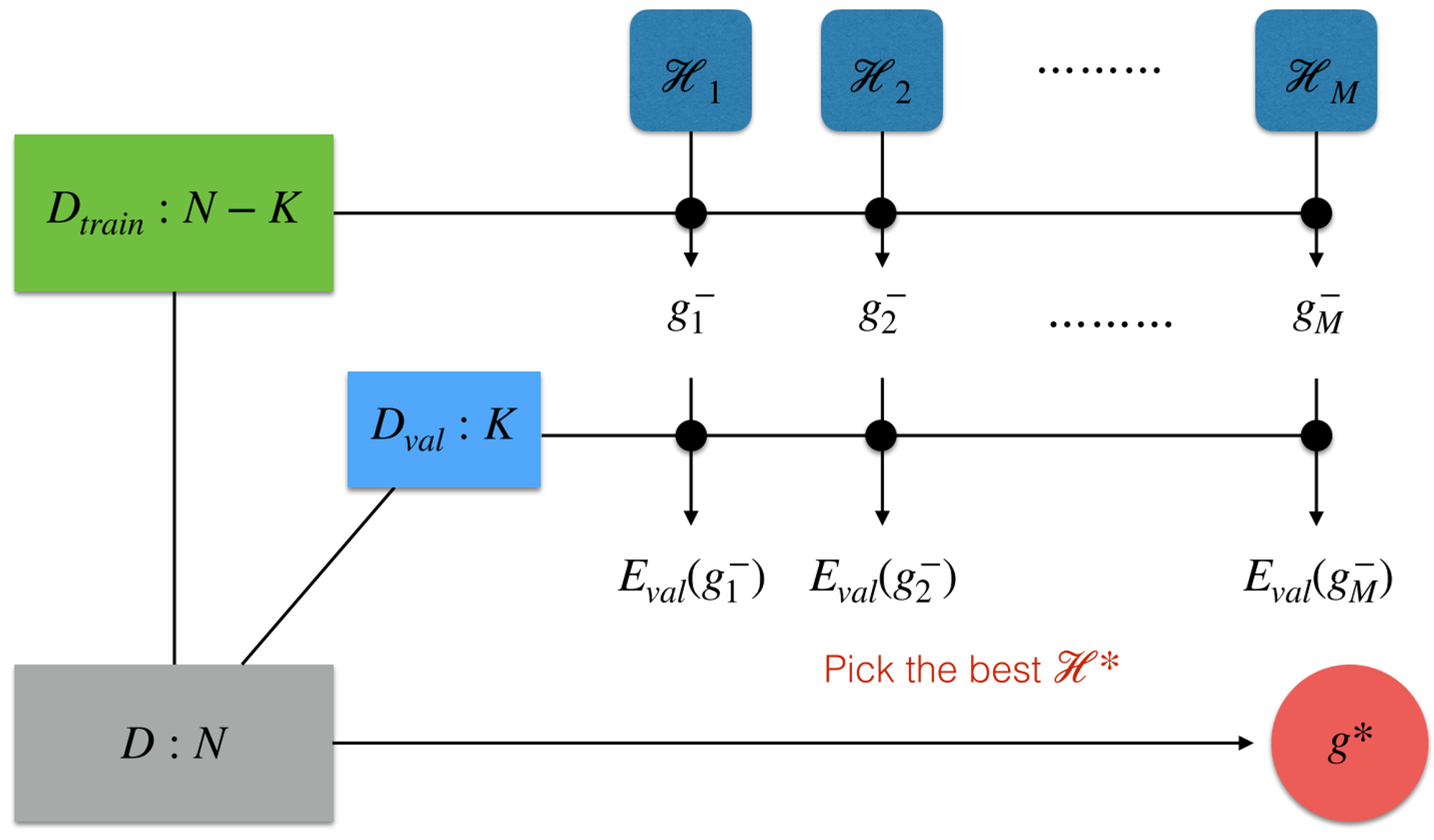
Model Selection
Use the same validation set multiple times without loosing guarantees
Assume you have models (hypothesis sets):

Cross Validation
Small K:
Large K:
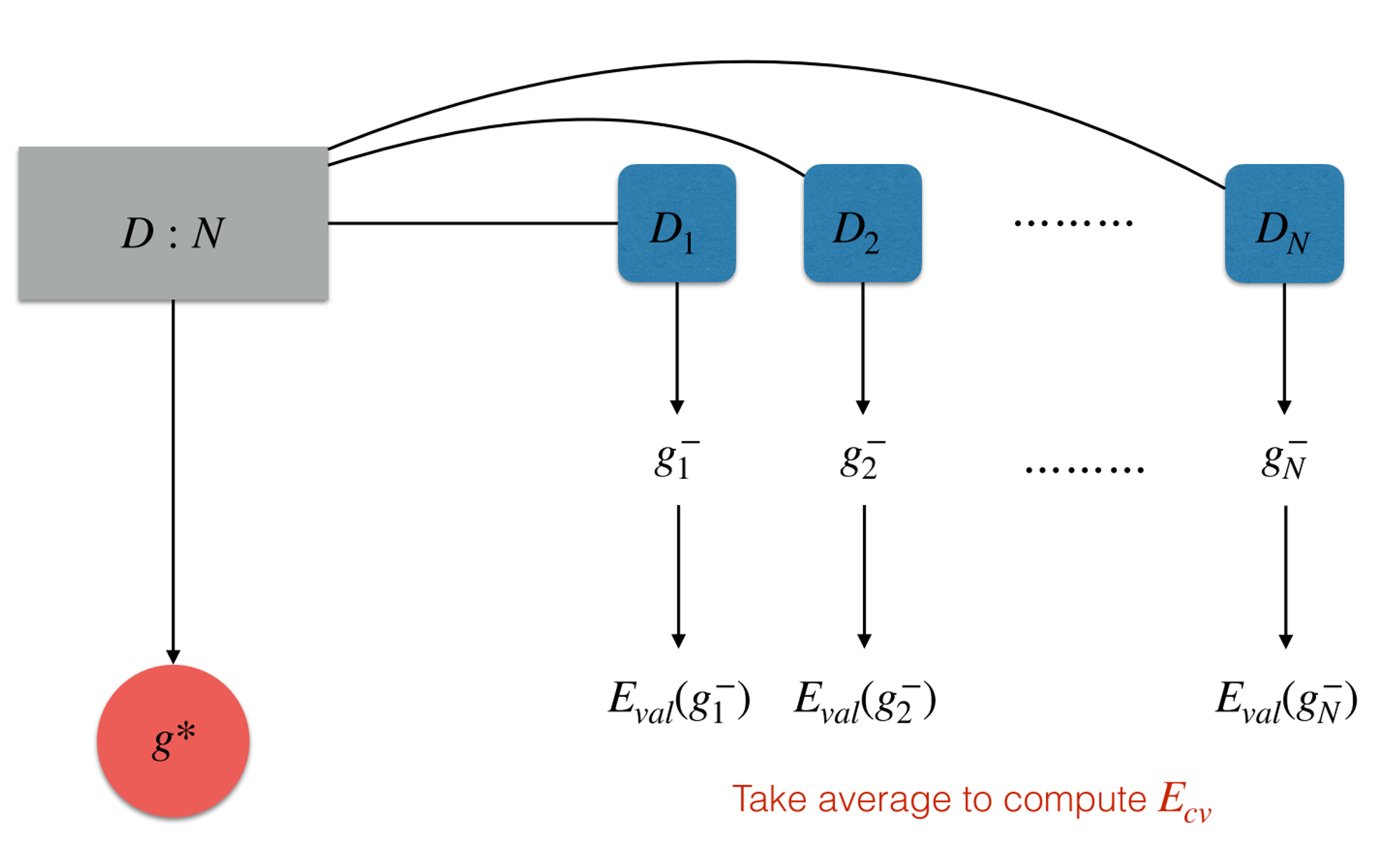
Leave One Out Analysis


- Leave 1 sample out, use the rest to train the model
- Compute model error with the 1 sample
- Repeat step 1 & 2 for times
- Compute the Cross Validation Error

Pros & Cons
Pro: Far more accurate
Con: Very expansive
- The Model is trained times
Model Selection with Cross Validation
- Define models by choosing different values of :
- For each model :
- Run the cross validation module to get an estimate of the cross validation error
- Pick the model with the smallest error
- Train the model on the entire training set to obtain the final hypothesis
Bayesian Decision Theory
Bayes Rule

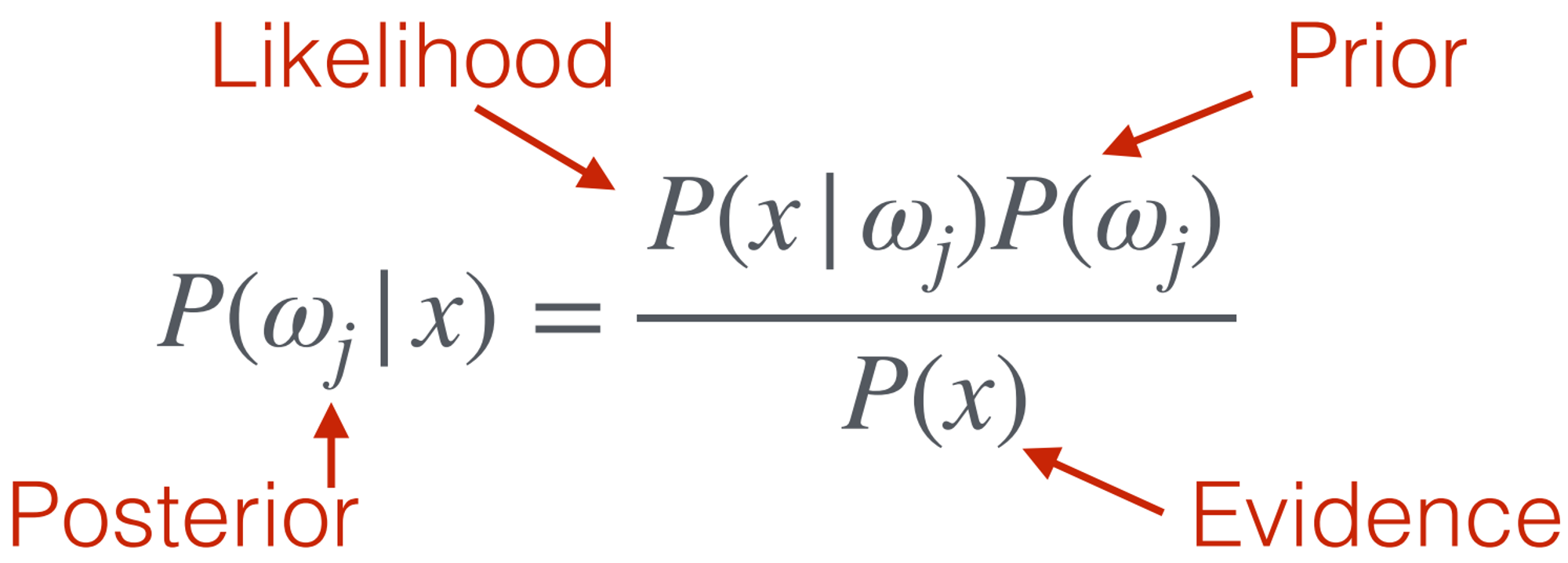
Given
- State of nature :
- Prior probabilities
- Class conditional probability: ,
To Find: Posterior Probability
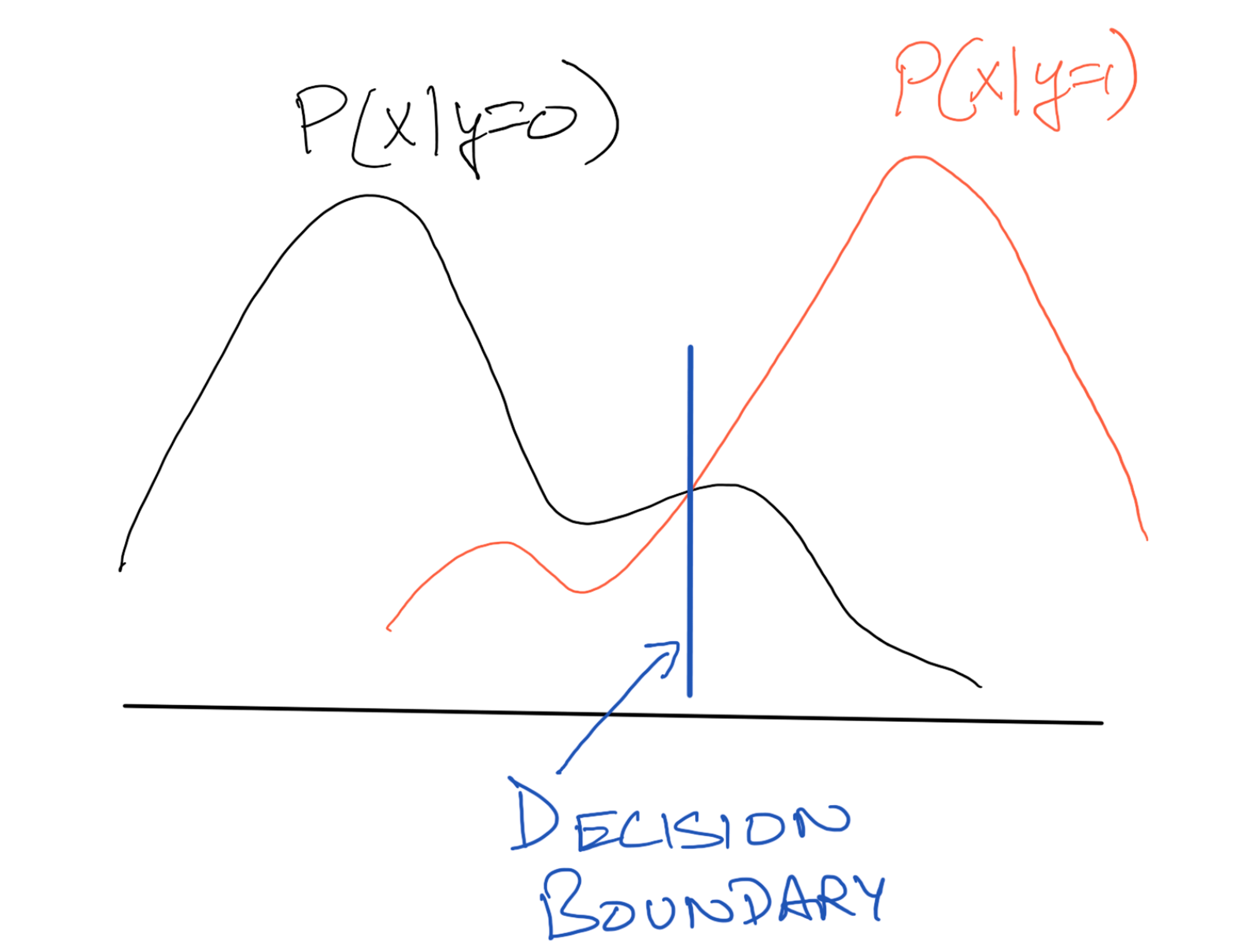
Error
if we decide on
if we decide on
Evidence is a scaling factor ⇒ Pick if otherwise
Conditional Risk
multi-dimensional observations represented as a vector
Bayes Theorem
Evidence
Conditional Risk
Expected loss associated with taking an action when the true state of nature is
Bayes Decision Rule
To minimize the overall risk, compute & take action to minimize conditional risk for
Frequentist vs Bayesian Approach
Bayesian Parameter Estimation
- Start with prior distribution
= prior knowledge about parameters before looking at the data
- Given a data set
- Use the Bayesian Theorem to find the posterior distribution of given
- Denominator = dist of data
Example: Logistic Regression
⬆️ The product term
Maximum A Posteriori Estimation
Bayesian Linear Regression
Generative vs Discriminative Models
How to Choose a Prior


Objective
Subjective
Conjugate
?? Learning
Prior = posterior of the previous iteration
Naive Bayes Classifier
Assumes all features are conditionally independent of other features
⇒ only depends on y
⇒
Reduce params to
Generative Model