
Created
Sep 9, 2021 06:36 PM
Topics
Linear RegressionModel CompositionLoss Function (Error Metric)Residual Sum of SquaresTrainingMaking PredictionModel AnalysisSignificance of a Single ParameterSignificance of a Group of CoefficiantsRegularization (Shrinkage Methods) Penalty UsageRidge RegressionUsageModelLoss FunctionClosed Form SolutionLASSO (Least Absolute Shrinkage and Selection Operator) RegressionUsageModelBias-Variance AnalysisPurposeFormulaExample
Linear Regression
Model Composition
-dimensional Input Vector
Learnable Parameter Vector
Target Function : assumed linear
Hypothesis Function : any linear function of parameters
Loss Function (Error Metric)
Measures the discrepancy between the model prediction and the actual value on the training set
Residual Sum of Squares
Training
Adjust to minimize loss
- Matrix Representation of the Hypothesis
Subsume intercept/bias into the parameter vector : Augment input vector by 1:
- Compute the derivatives of and set it to zero
- Solve for the closed form solution
Making Prediction
For a new observation , its prediction can be computed as
Model Analysis
Significance of a Single Parameter
= variance of the observations assumed uncorrelated with constant variance
For any variable define the Z-score as
- is the diagonal element of
Result: smaller → less important
Significance of a Group of Coefficiants
F-statistics: measures the change in residual
- = residual sum of squares of the bigger model with parameters
- = residual sum of squares for the nested smaller model
Regularization (Shrinkage Methods)
机器学习 = 训练集上的最小化问题 ⇒ 容易过拟合
为对抗过拟合,向损失函数中加入描述模型复杂程度的正则项
Regularized Loss Function = Loss Function + Penalty Term
Penalty
- = Regularization parameter
- = weight associated with the variables
- generally considered to be the -norms
Usage
- Help adjust complexity of hypothesis space
- Balance fitness and generalizability
Ridge Regression
Implementation of
- Penalty = squared magnitude (-norm) of coefficients
Usage
- Shrink the coefficients but greater than 0
- Confine hypothesis space ⇒ make it smaller than the space of all linear functions
- Output non-sparse
Model
- Minimize
- Subject to constraint
Rewritten as
Lagrangian MultiplierLoss Function
Closed Form Solution
LASSO (Least Absolute Shrinkage and Selection Operator) Regression
Implementation of Regularization
- Penalty = absolute value (-norm) of coefficients
Usage
- Penalize insignificant coefficients to zero
⇒ feature-selection method to remove useless coefficients
- Prefers sparsity: less terms ⇒ better
- With a lot of parameters, only some of them have predictive power
- Output is sparse: some coefficients are left out
Model
- Shrinkage Factor
Bias-Variance Analysis
Purpose
express in a way that helps choosing the hypothesis space
- How well can approximate
- How well we can zoom in on a good hypothesis
- A theoretical process: is not accessible in practice
Formula
Given:
- Dependence of on
- expectation over based on the distribution on
- Average hypothesis over multiple draws of


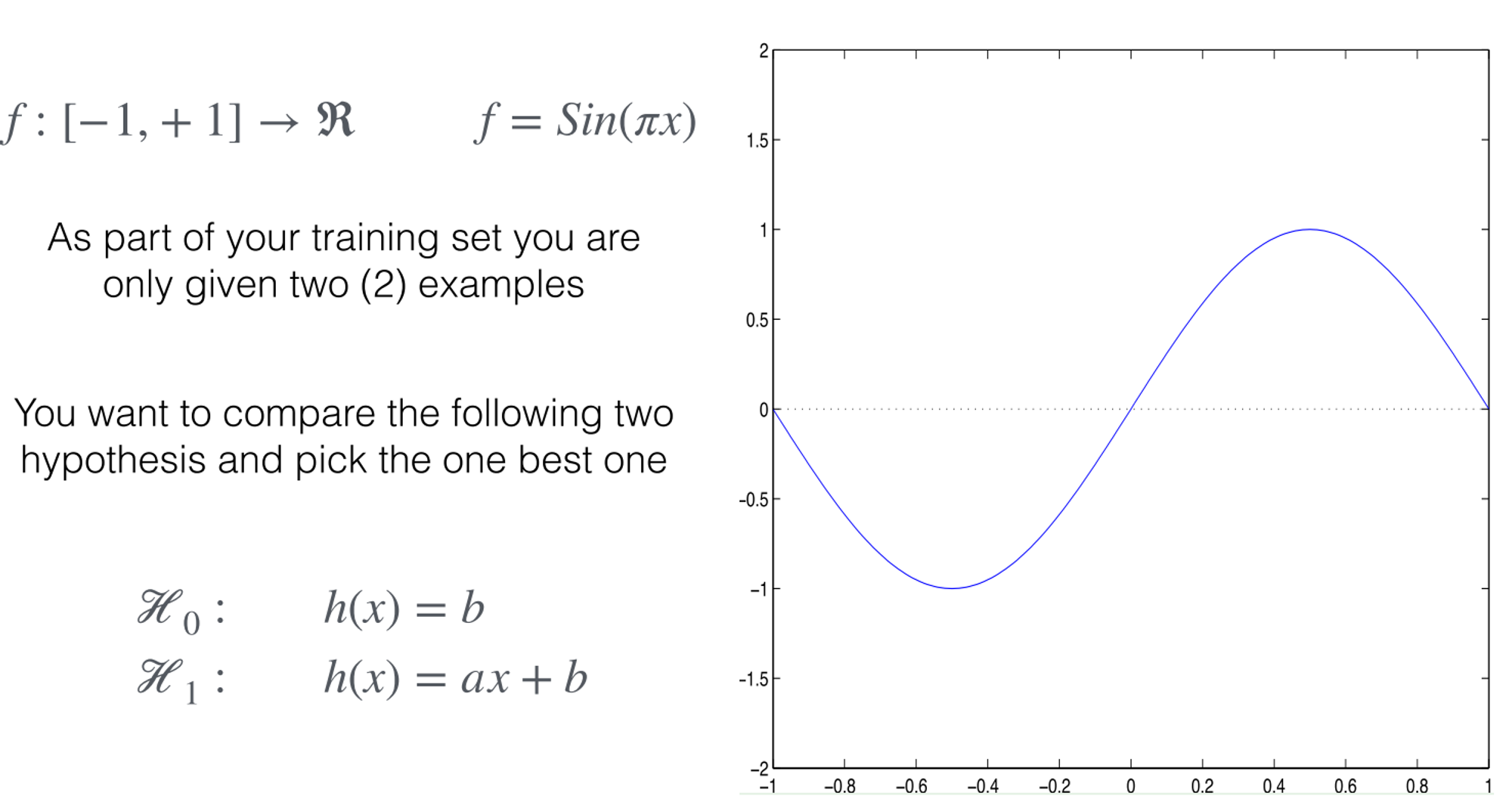
Example
Given:
🚫 : High bias | Low Variance
✅ : Low bias | High Variance
Which one is better?


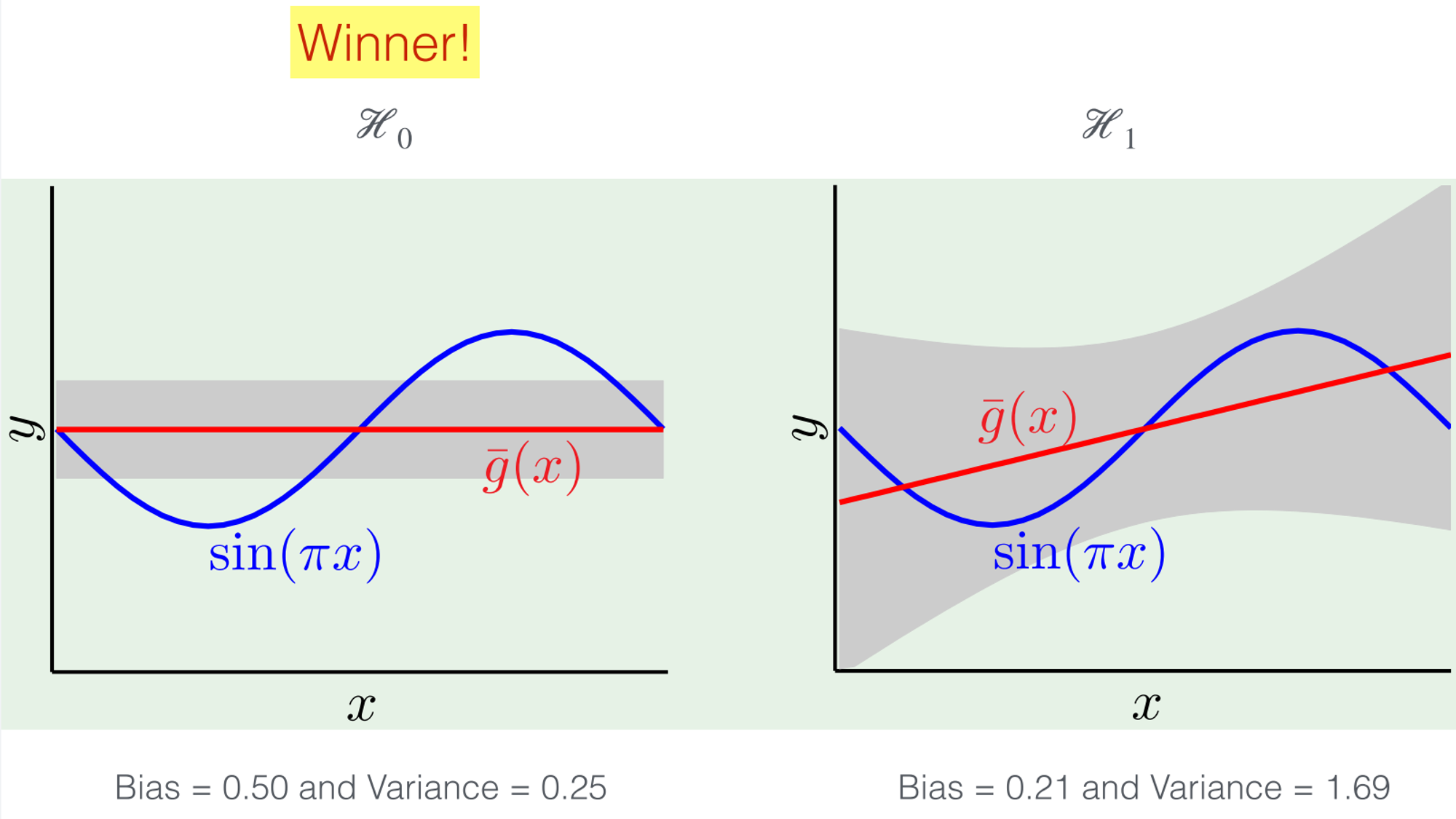
Match the model complexity to the data resources
NOT the target complexity ⇒ better generalizability
Stick to the simplest answer!! (Occam's Razor)
Multi-Class Classification
Use Logistic Regression models to classify classes
Likelihood for a Single Sample (Softmax Function)
The
softmax function is a function that turns a vector of real values into a vector of real values that sum to 1.Likelihood of the Data
Loss Function (Cross-Entropy Loss)
- value of output to the j-th

