
Created
Oct 19, 2021 06:24 PM
Topics
XOR, Backpropagation Algorithm
Lecture OutlineArtificial NeuronOR vs XORActivation FunctionsTwo-Layer Neural NetworkModelWeight MatrixGeneral Neural NetworkUniversal ApproximatorTraining Neural NetworksRegression TaskLikelihood functionLoss FunctionClassification TaskCross Entropy LossTraining Using Gradient DescentTraining Using Backpropagation Algorithm➡️ Forward PassExample: Single Neuron Per Layer⬅️ Backward PassRegularizationWeight DecayEarly stoppingDropoutConvolutional Neural Networks (CNNs)Motivation
Lecture Outline
- Motivation behind neural networks
- The XOR problem
- Multi-Layer Perceptron model
- Backpropagation algorithm
- Regularization and other stuff in NNs
Artificial Neuron

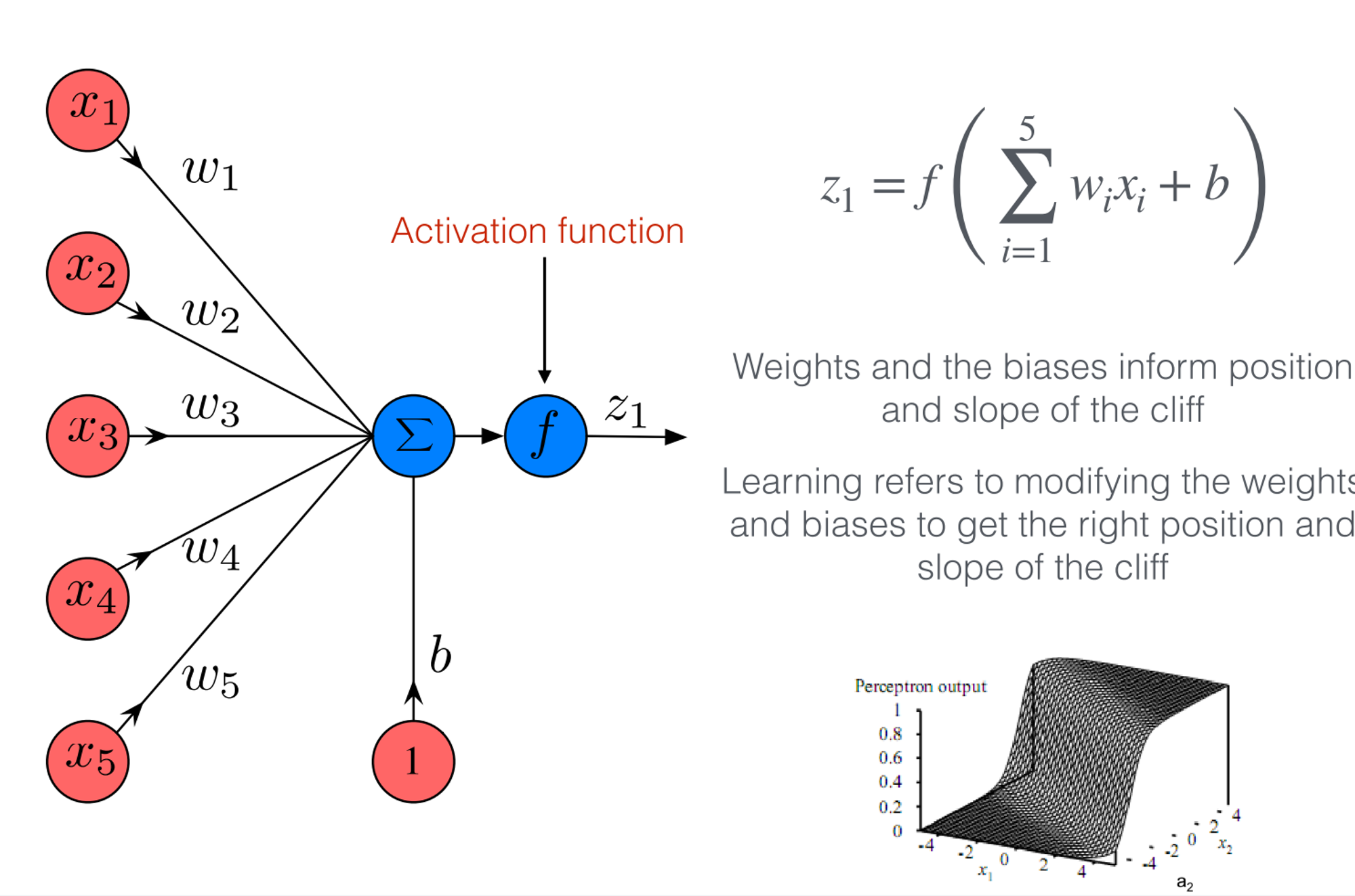
OR vs XOR
TODO
Activation Functions
Introduce non-linearity to the model
- Sigmoid
- ReLU
Choosing activation function: an art not a science
- Stick to one activation function for all layers
Two-Layer Neural Network
Single-hidden-layer network
Potentially overfits the dataset
Can simulate any line (linear or non-linear)

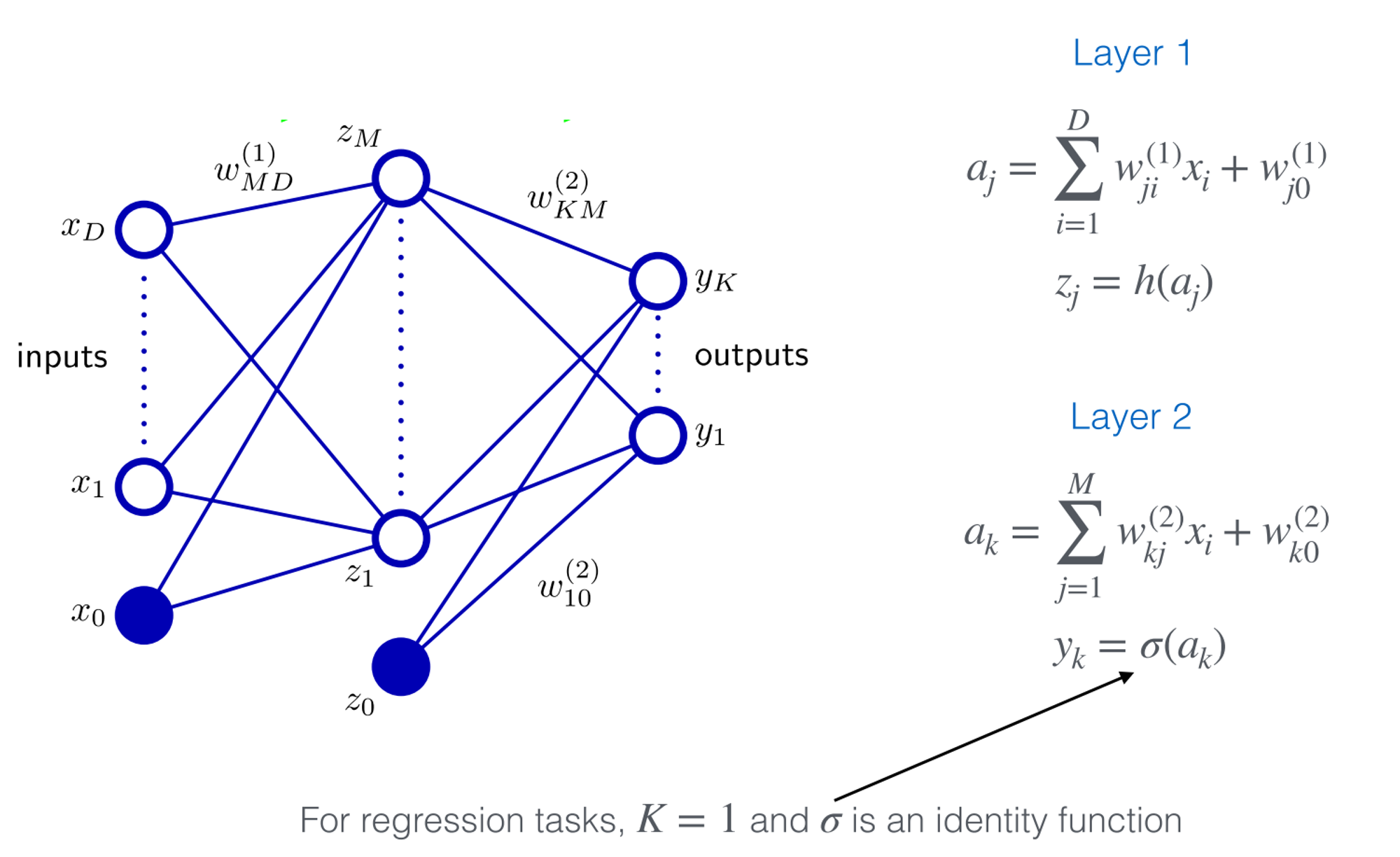
- number of hidden layers (depth of network ) ⇒ number of hyperplanes
- Deep learning: many hidden layers
- any activation function (sigmoid, ReLU, etc.)
For regression tasks: , identity function
For binary classification task:
Model
Weight Matrix

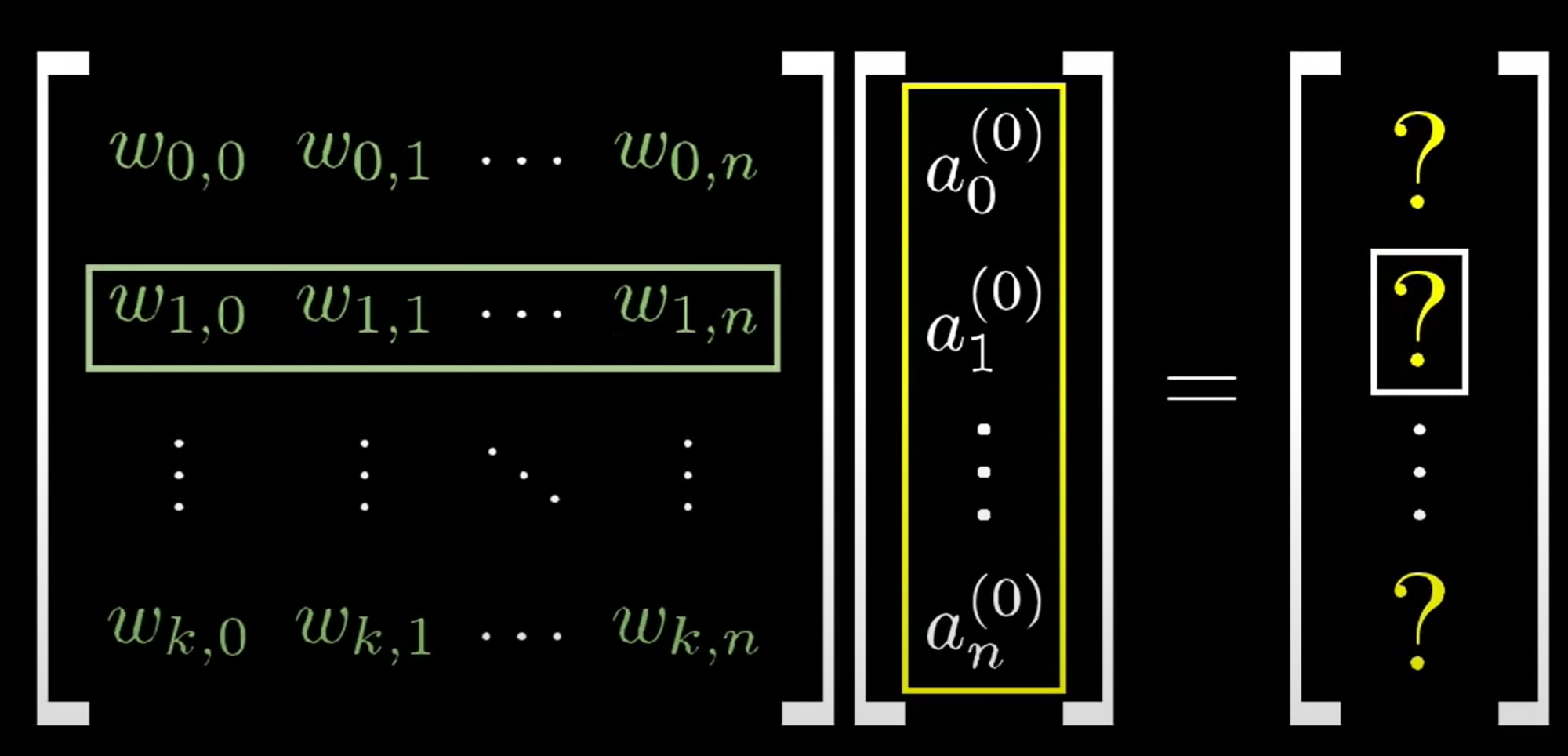
Shape of
- rows ⇒ # neurons in the next layer
- columns ⇒ # neurons in the current layer
Each row in corresponds to the output of the next layer
General Neural Network
A directed acyclic graph from left to right


k = unit for which compute activation for
j = input for unit k
Universal Approximator
A two layer neural network can approximate any function
Training Neural Networks
Regression Task
Likelihood function
Loss Function
Classification Task
Cross Entropy Loss
Training Using Gradient Descent
Gradient is hard to find due to model complexity
Training Using Backpropagation Algorithm
Message passing algo with 2 steps:


➡️ Forward Pass
starting from the inputs successively compute the activations of each unit
- Apply input to the network
- Compute the activations of all units (hidden & output)
- Evaluate for all output units
- ground truth
- prediction of the model
Example: Single Neuron Per Layer
Structure


Formulas




⬅️ Backward Pass
successively compute the gradients of the error function with respect to the activations and the weights
- First compute the gradient of the output
- Backpropagate to compute for all hidden units
Given and
- Evaluate the derivatives w.r.t. weights :
Regularization
Weight Decay
Early stopping
Stop training as soon as the validation error starts increasing
Training Loss
Validation Loss

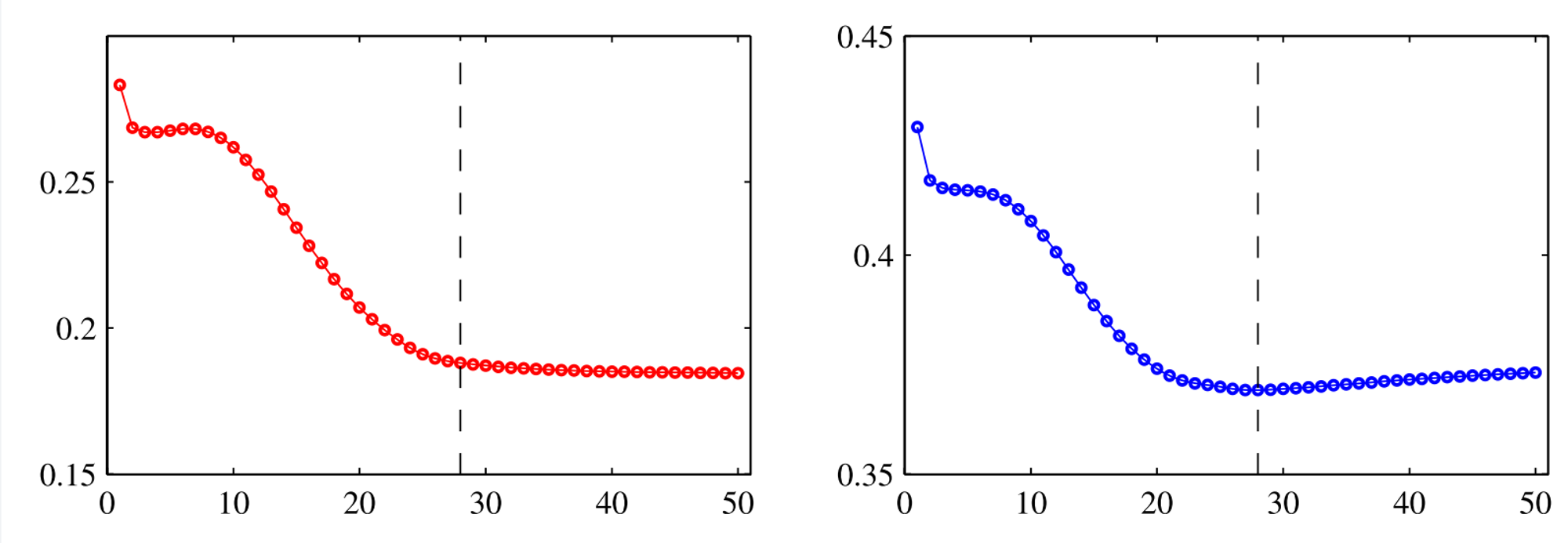
⇒ Equivalent to some kind of weight decay
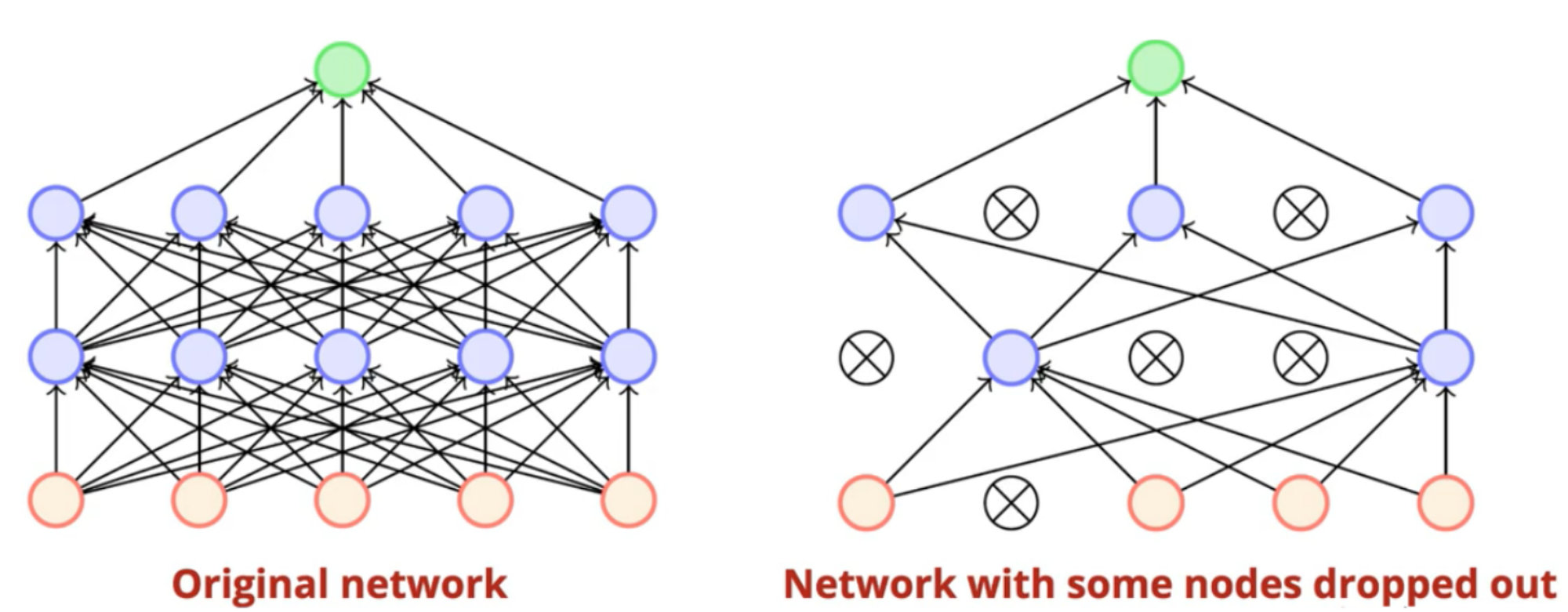
Dropout
During each training iteration, remove from the model (turn off) each unit with a probability of
turned off ⇒
- Validate & test using the full model, scale each unit by the frequency at which it is on

Convolutional Neural Networks (CNNs)
Motivation
Neural Network Convention

Problem: Output should be invariant to translation, rotation, scaling, distortion, elastic deformation, other arbitrary artifacts
Naïve Solution: Fully Connected Networks w/ a large & diverse data to obtain invariance
- Each unit of each layer sees the whole image
- Ignores the key property of images: locality - near by pixels tend to have similar values
- Neural Networks are brittle ⚠️: small variances → big effect on output
- Information can be merged at later stages to get higher order features about the whole image

