
Created
Oct 5, 2021 06:08 PM
Topics
Dual Form Solution, Kernel Trick, Hinge Loss
Logistic Regression ReviewThe Perceptron ModelSupport Vector MachineNotationsFunctional Margin ScalingGeometric Margin Property 1Property 2Property 3Geometric Margin of a Particular ClassGeometric Margin of Both ClassesGeometric Margin for the Data SetMaximum Margin ClassifiersConstrained Optimization Problem1️⃣ Primer SVM Problem Statement Optimization OverviewUnconstrained OptimizationConstrained OptimizationLagrangian MultiplierDual Problem Statement Conditions for SolutionsKKT (Karush-Kuhn-Tucker) Conditions2️⃣ Dual SVM Problem Statement The Lagrangian is Given ByKKT ConditionsDual formulationSolutionUnderstanding the ConstraintsPredictions with SVMsNaïve ApproachBetter ApproachSummaryWhen Linear Separability Does Not ExistSolution 1: Find s.t. min # of constraints are violatedSolution 2: Minimize Slack PenaltyHinge LossIntuitionFormulationLoss Functions
Logistic Regression Review


Multi-Class Classification
Use Logistic Regression models to classify classes
Likelihood for a Single Sample (Softmax Function)
The
softmax function is a function that turns a vector of real values into a vector of real values that sum to 1.Likelihood of the Data
Loss Function (Cross-Entropy Loss)
- value of output to the j-th
The Perceptron Model
Bias pushes the hyperplane toward the decision boundary


Support Vector Machine
Seeks large margin separator to improve generalization
- Largest margin: farthest from the 2 classes
Uses optimization to find efficient and optimal solutions
Uses kernel trick to make computations efficient specially in cases where the feature vectors is huge
- Projects data to a high-dimensional space


Notations
Input:
Output (labels):
Parameters:
Bias (Intercept):
Functional Margin
Large margin → correct prediction & high confidence
Functional margin of a single training sample w.r.t.
- If then for to be large we need
- If the for to be large we need
Note that when the above is true, the prediction is also correct:
Scaling
Normalize the parameters to ensure without affecting the solution
- is invariant under scaling
- is not invariant under scaling
Geometric Margin
Distance of from the hyperplane
Property 1
Unit vector hyper-plane
- For lying on the hyper-plane
Property 2
For any points on the hyper-plane we have
Property 3
Signed distance between any point to the hyper-plane is given by

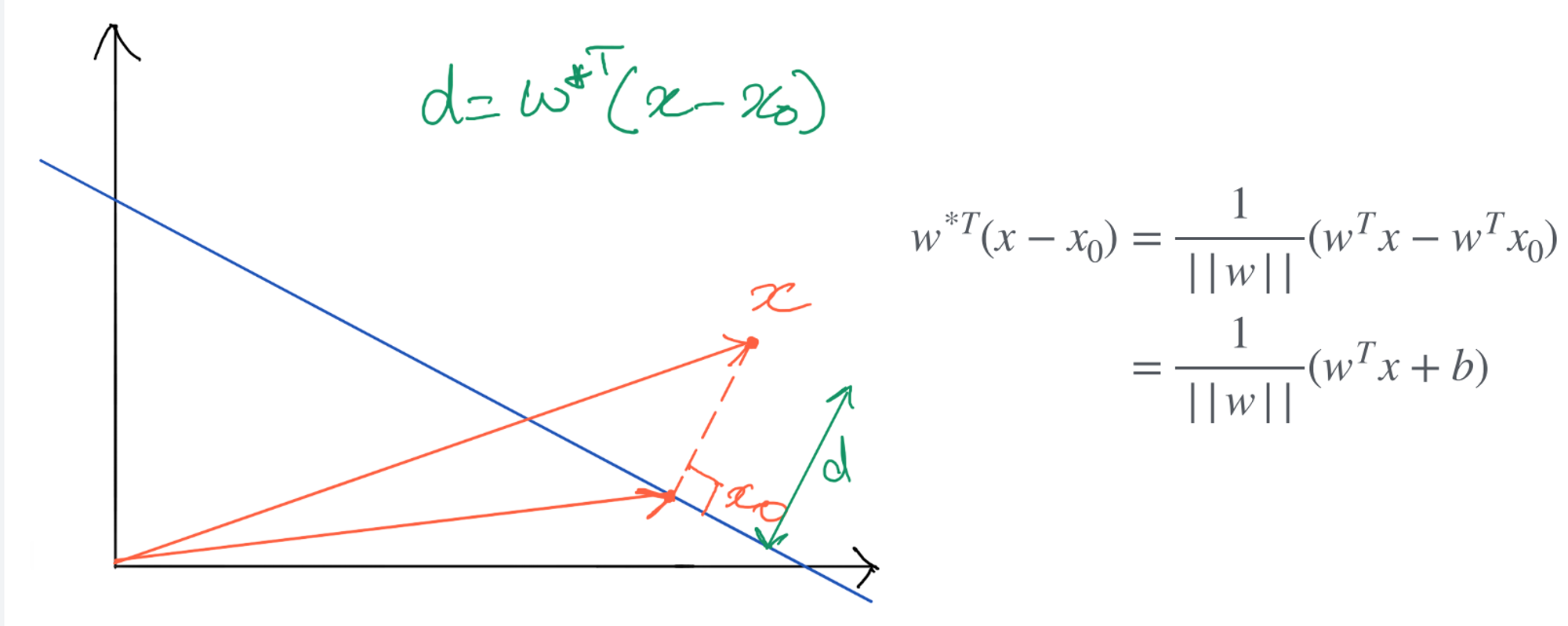
Geometric Margin of a Particular Class
Geometric Margin of Both Classes
- A scaled version of Functional Margin
- invariant to scaling of parameters
Geometric Margin for the Data Set
Distance to the closest point of either of the classes
Maximum Margin Classifiers
Maximize the distance to the closest point of either of the classes
- Discards other points, only care about the closest
Assumption: is linearly separable
Constrained Optimization Problem
Constraints
- Geometric margin ≥ : Make sure all points are further than → then maximize
- imposed to ensure Functional Margin = Geometric Margin
- simplifies equation
- L-2 norm
Simplify: Use Functional Margin Instead
- Remove constraint
- Modify Objective to
- (scaling constraint on )
1️⃣ Primer SVM Problem Statement
Goes directly for the
Simplified from the definition above
- Convex quadratic optimization with linear constraints
Optimization Overview
Unconstrained Optimization
Constrained Optimization
Equality constraint ↔️ 2x inequality constraint
Lagrangian Multiplier
Reduces a problem with variables with constraints
to an unconstrained problem of variables
- Introduce a to each constraint
- Compute the linear combination of multipliers & constraints
- Optimize the wrt ↔️ evaluating at
If satisfies all the constraints
Solution to is the same as
Dual Problem Statement
A reduction of the primer problem
- always true
- sometimes true under certain conditions
Conditions for
- are convex
- is affine/linear:
- strictly possible:
Solutions
satisfying the KKT conditions
- solves the primal problem
- solves the dual problem
KKT (Karush-Kuhn-Tucker) Conditions
Complementarity Condition ➡️ ➡️ constraint is active
2️⃣ Dual SVM Problem Statement
The Lagrangian is Given By
KKT Conditions
Dual formulation
Solution
Understanding the Constraints
➡️ Either or
➡️
The hyperplane is defined by only the few closest data points

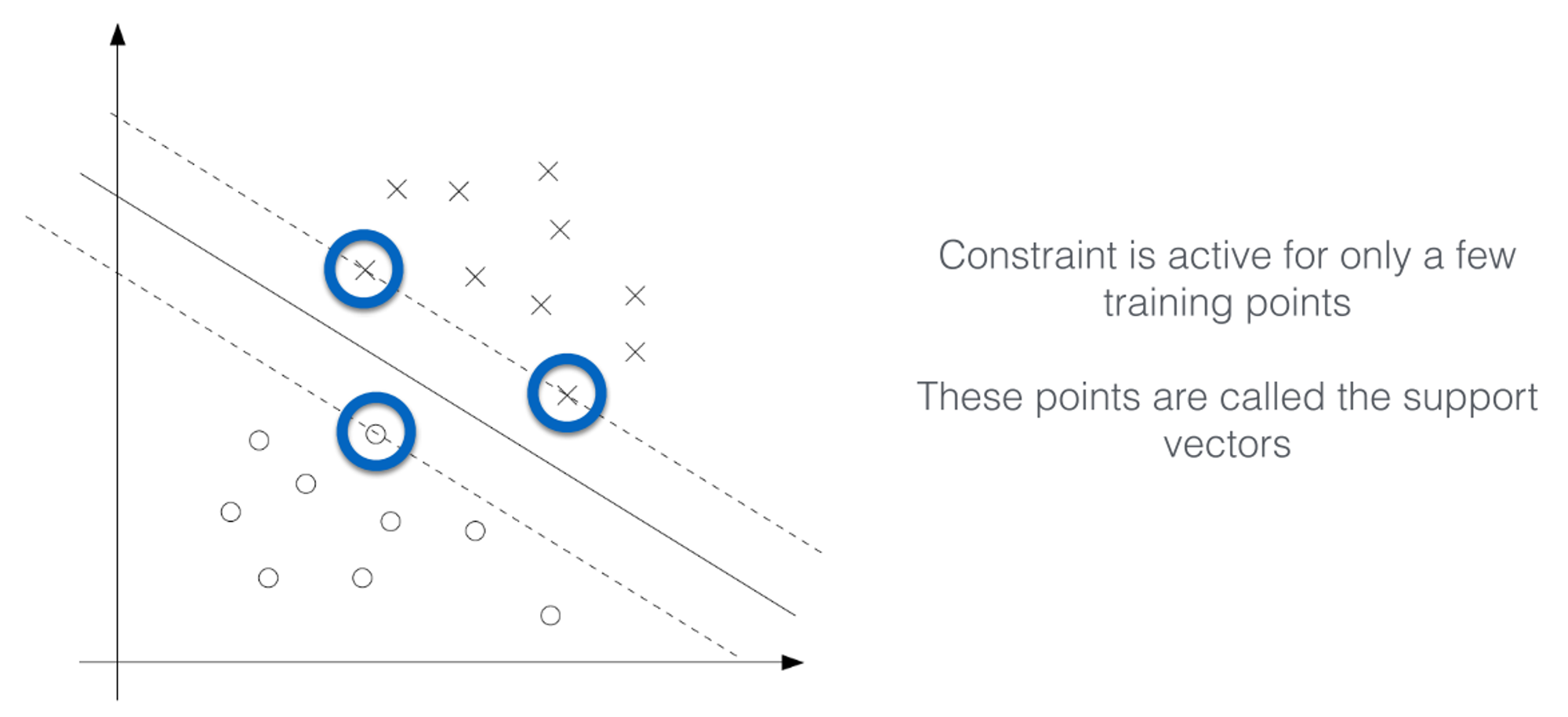
Predictions with SVMs
Naïve Approach
Compute ; assign class +1 if positive, class -1 if negative
Better Approach
Summary
When Linear Separability Does Not Exist
All constraints are violated
⇒ Geometric margin loses its meaning
Solution 1: Find s.t. min # of constraints are violated

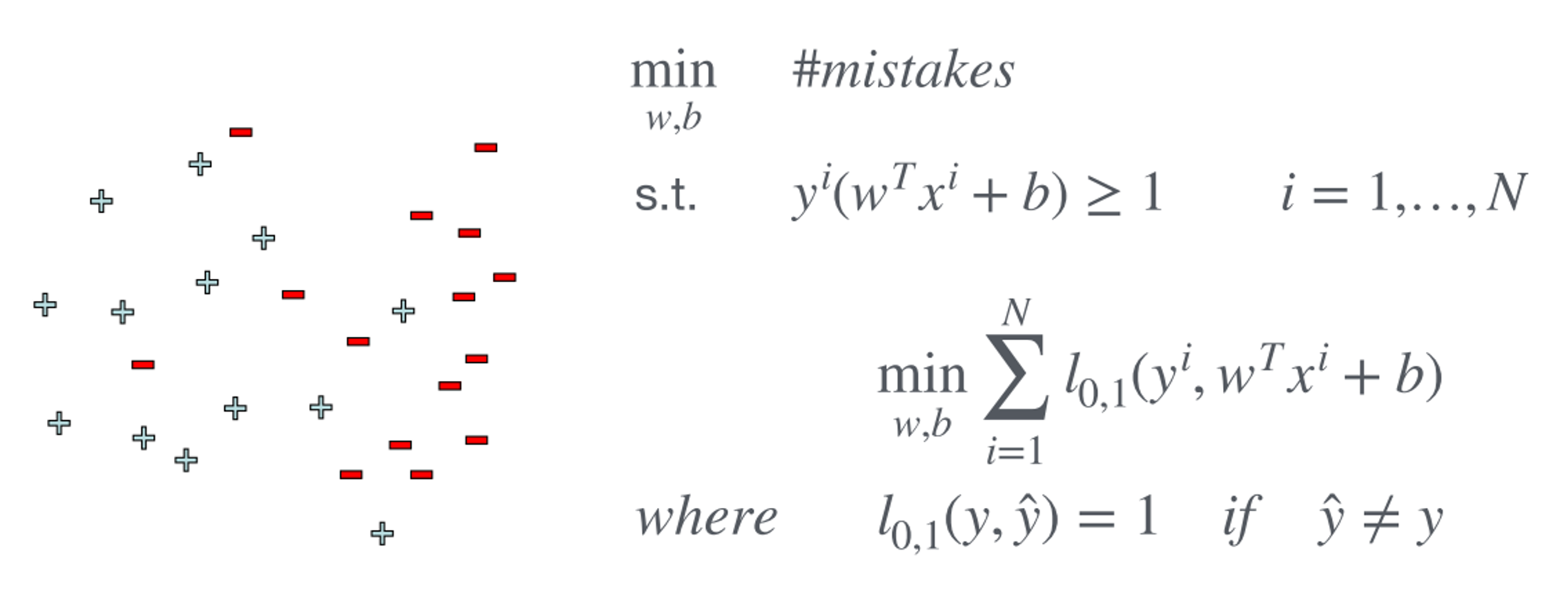
⇒ NP-Hard Problem
Solution 2: Minimize Slack Penalty
If functional margin is ≥ 1, the no penalty
If functional margin is < 1, then pay linear penalty

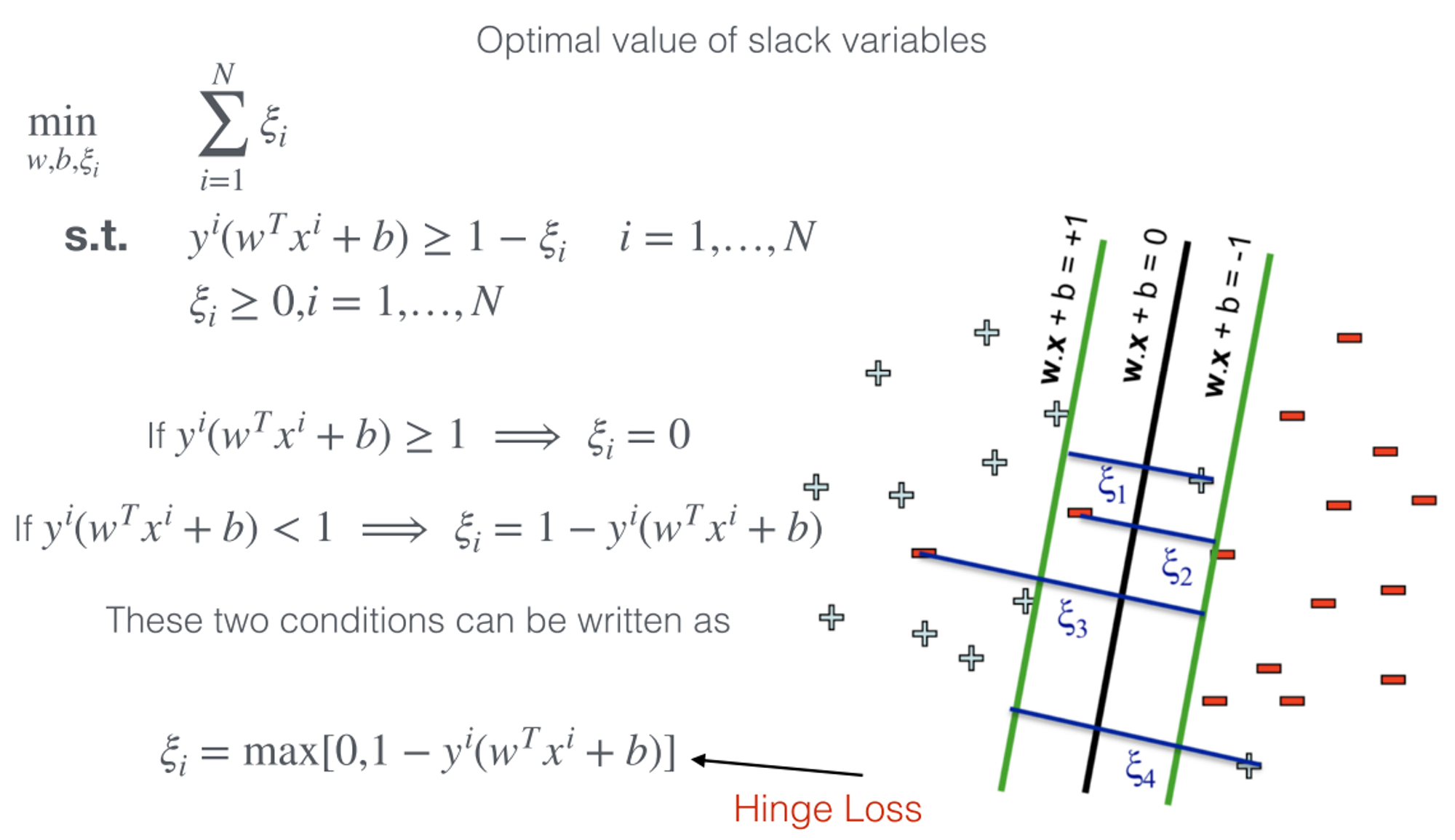
Hinge Loss
This is the tightest convex upper bound of the intractable 0/1 loss

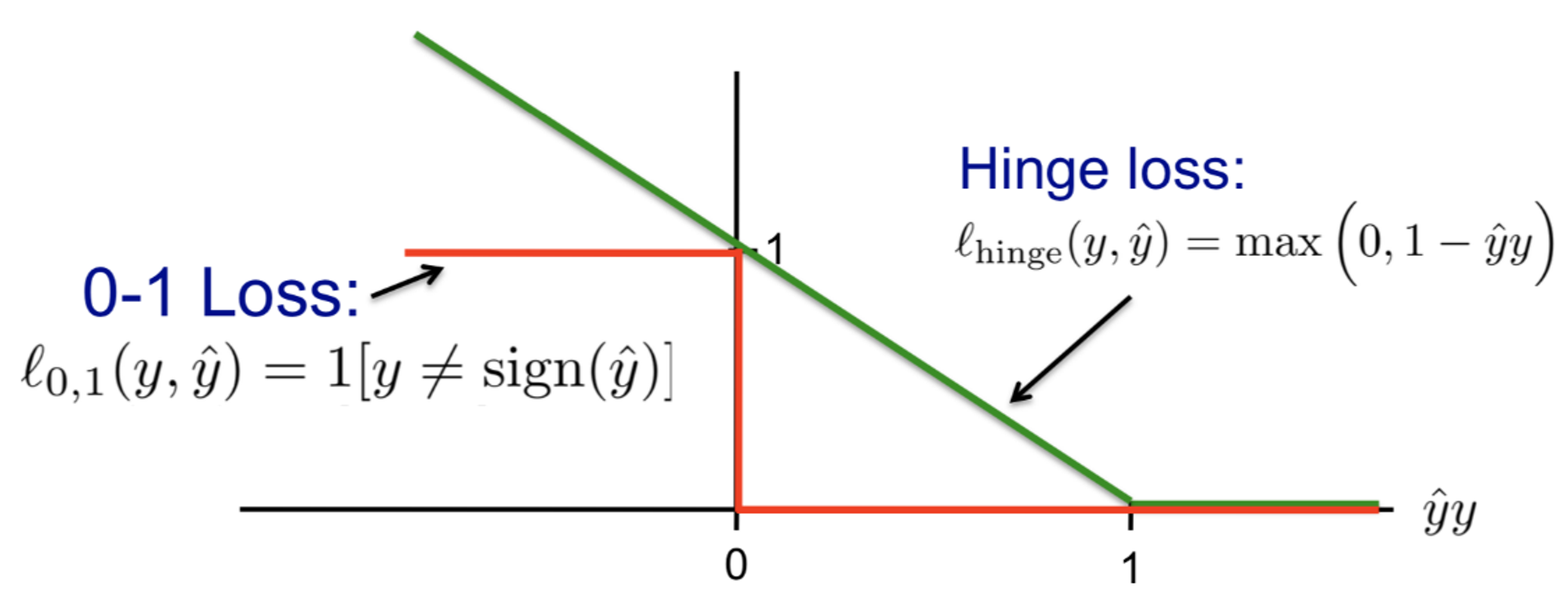
Intuition
⇒ same sign ⇒ correct classification ⇒
⇒ different sign ⇒ incorrect classification ⇒
Formulation
If then you have to separate the data ⇒ linearly separable solution only
If then completely ignore the data
Optimization over Hinge Loss with an regularization term




