
Created
Sep 14, 2021 04:39 PM
Topics
❓ Why Not Linear Regression📈 Logistic Regression ModelPropertiesHypothesis RepresentationLogistic (Sigmoid) Function Soft Threshold (Conversion to from signal)Why SigmoidInterpretation of Hypothesis OutputTarget FunctionDecision BoundaryNon-Linear Decision BoundariesExample from Intro2MLExample from Andrew NgMethod to Find Best-Fit LineLoss FunctionGoal: Maximum Likelihood EstimationIn PracticeCross-Entropy LossLogistic Regression Algorithm w/ Gradient Descent⌛ Iterative Optimization📦Batch Gradient DescentProcedureFormulaInsightsChoosing Step Size 🥚 Stochastic Gradient Descent🧺 Mini-Batch Gradient DescentComparing Gradient Descent Variants🤔 QuestionsResources
❓ Why Not Linear Regression
Poor performance w/ classification problems
- Need to set an arbitrary threshold
- Outliers significantly reduce power of model
- Hypothesis' output value can be > 1 or < 0
📈 Logistic Regression Model
Usage: Classification
- predict the probability that an observation belongs to one of two possible classes
Similar to Linear Regression, but gives probability or True/False
Properties
Classification algorithm:
Hypothesis Representation
Maps linear regression to {0, 1} by nesting inside a Sigmoid function
Logistic (Sigmoid) Function


Soft Threshold (Conversion to from signal)


Why Sigmoid
- Smooth
- Easy to compute derivative / gradient
- Non linear: can model more complex relations
Interpretation of Hypothesis Output
estimated % that on input
Target Function
Probability that given ; parametrized by
- The data does not give us explicit probabilities
- Only provides samples generated
- Pick
As a binary classification problem (probability sums to 1):
Decision Boundary
A property of the hypothesis function & parameters
- Predict if
- Predict if
Logistic Function: Input ≥ 0 ⇒ Output ≥ 0.5
Therefore,
Non-Linear Decision Boundaries
Use higher-order polynomials to classify data with complex geometric shapes
Example from Intro2ML

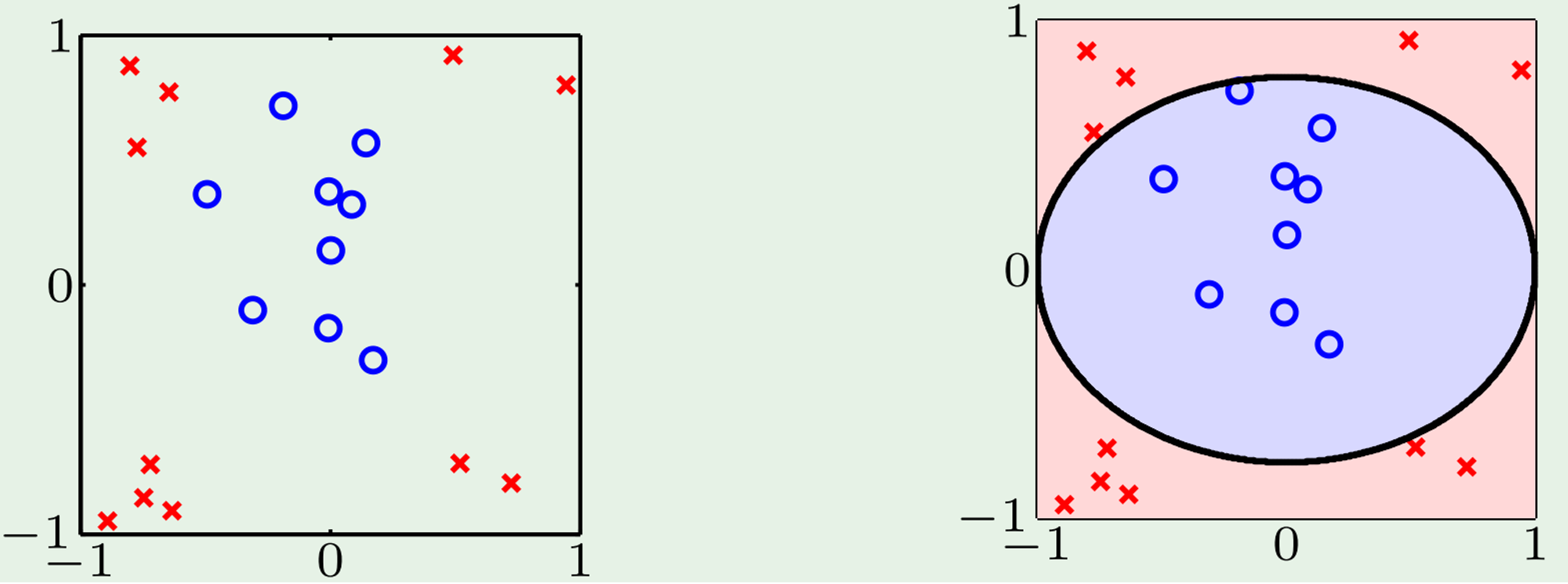
Apply Transformation

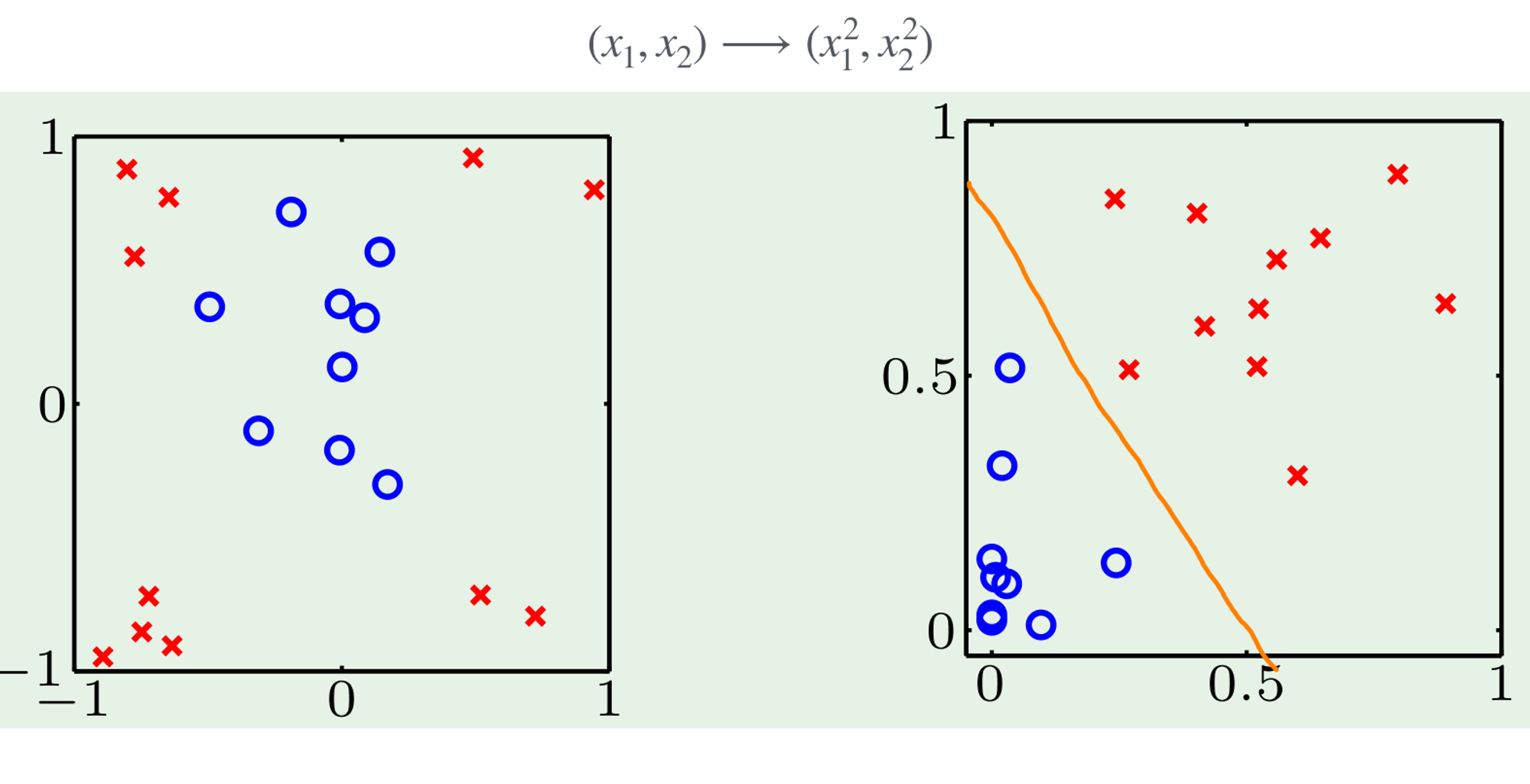
Then we can create a hyper-plane to separate the data for classification
Example from Andrew Ng


Difficulty: need to come up w/ transformation b4 inspecting data
Method to Find Best-Fit Line
Calculates maximum likelihood
- Pick a probability scaled by
- Calculate the % of
Loss Function
% that the predicted value is correct
Compute the likelihood of IID Training data
Goal: Maximum Likelihood Estimation
Adjust parameter to maximize likelihood
In Practice
Take of the likelihood to minimize
- Equivalent since the function is monotonically decreasing
Cross-Entropy Loss
This error measure is small when is large and positive
- pushes to classify each correctly
Logistic Regression Algorithm w/ Gradient Descent

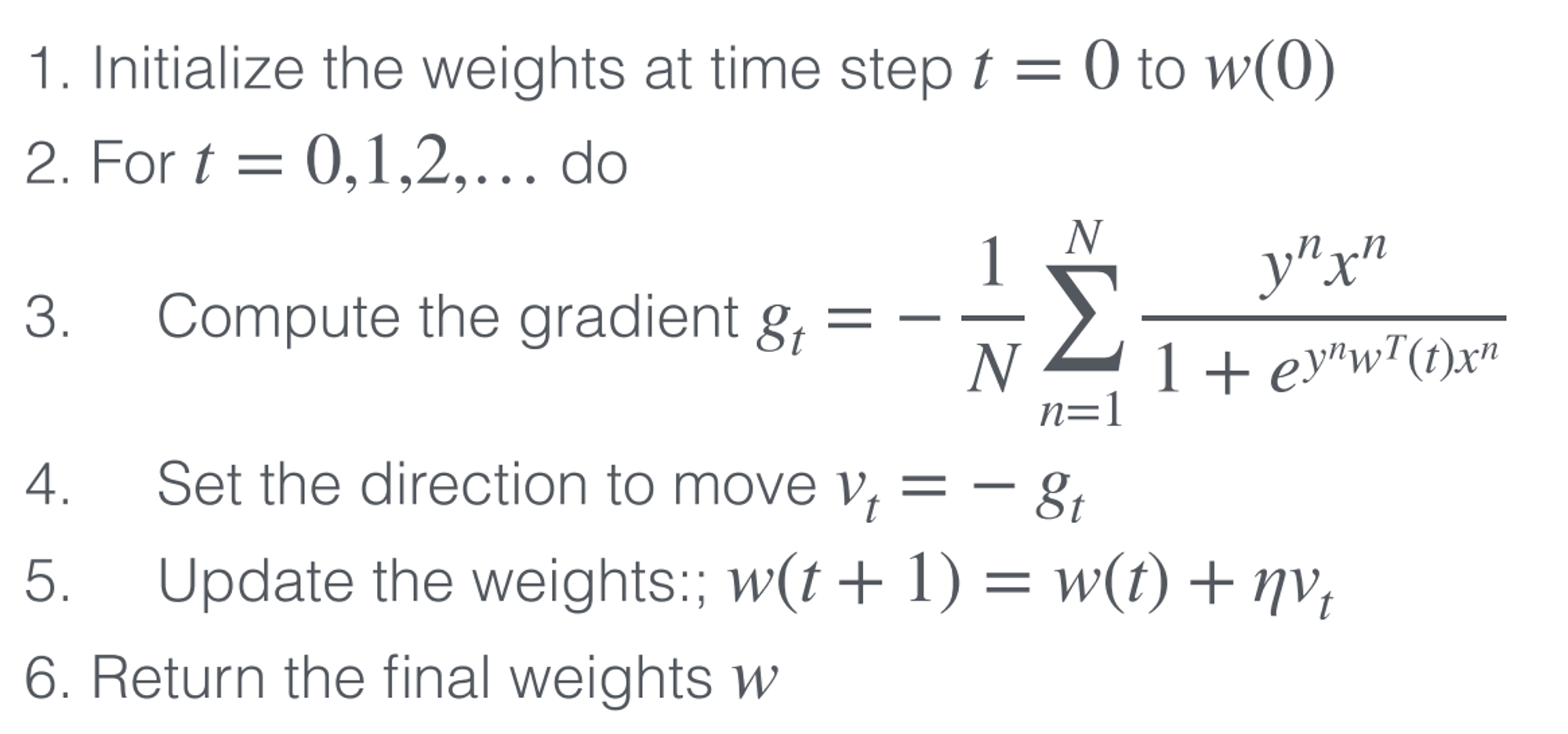
⌛ Iterative Optimization
Minimize the loss function → make the model more useful
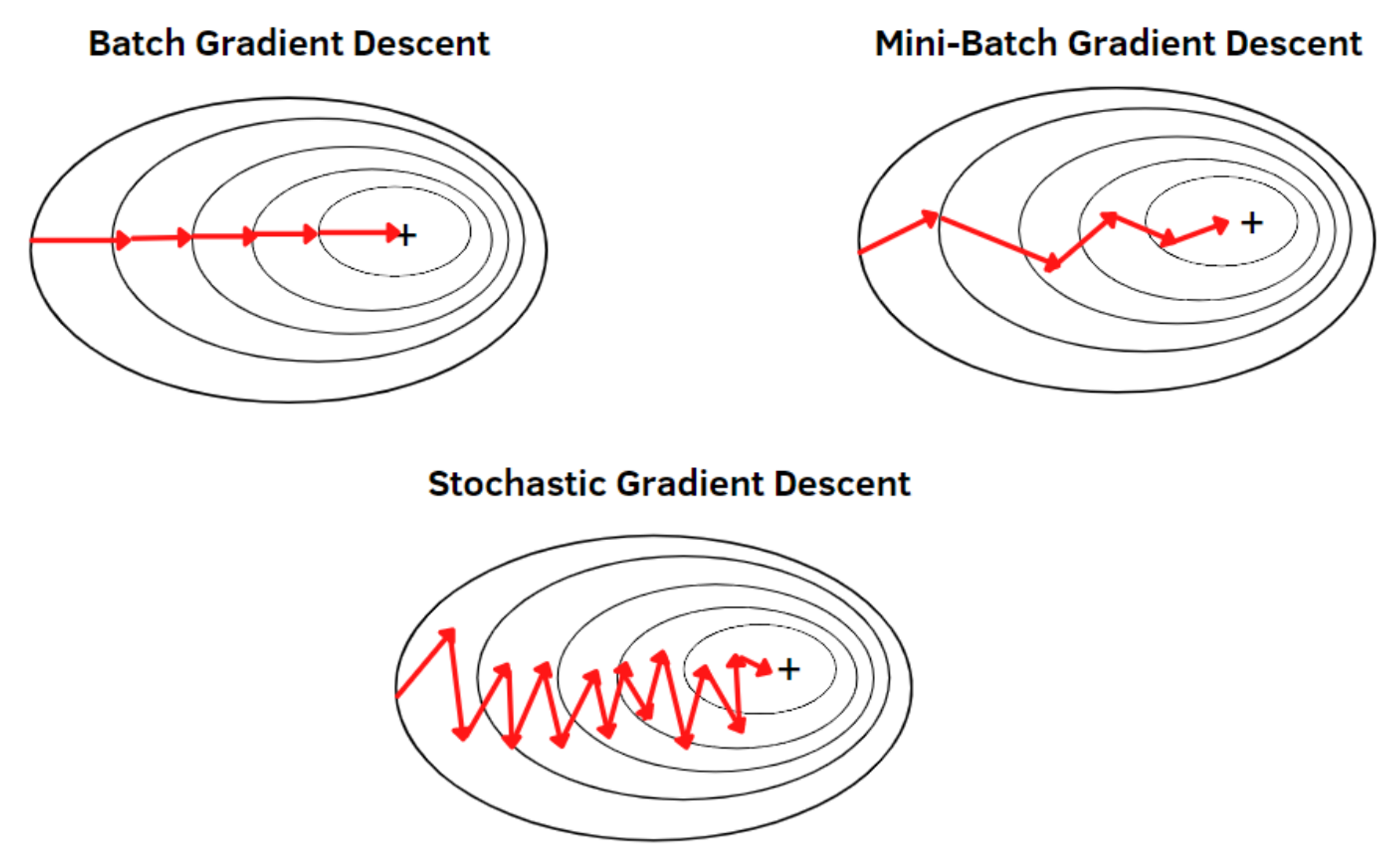
📦Batch Gradient Descent
An optimization technique to compute logistic regression & other learning algorithms
Sliding Down Hill: progressively modifies parameter in a way that decreases error
- Computing 2nd derivative is almost impossible in most cases
- Gradient descent provides a close estimate


Procedure
- Start with an initial value of parameters
- Compute the direction at which weight decreases
- Update the parameters in that direction
- learning rate (how big the step we take)
Formula
Insights
- Take a step in the direction of steepest descent to gain the biggest decrease of E
Using first order Taylor expansion we compute the change in
Since is a unit vector, this equality holds
iffChoosing Step Size

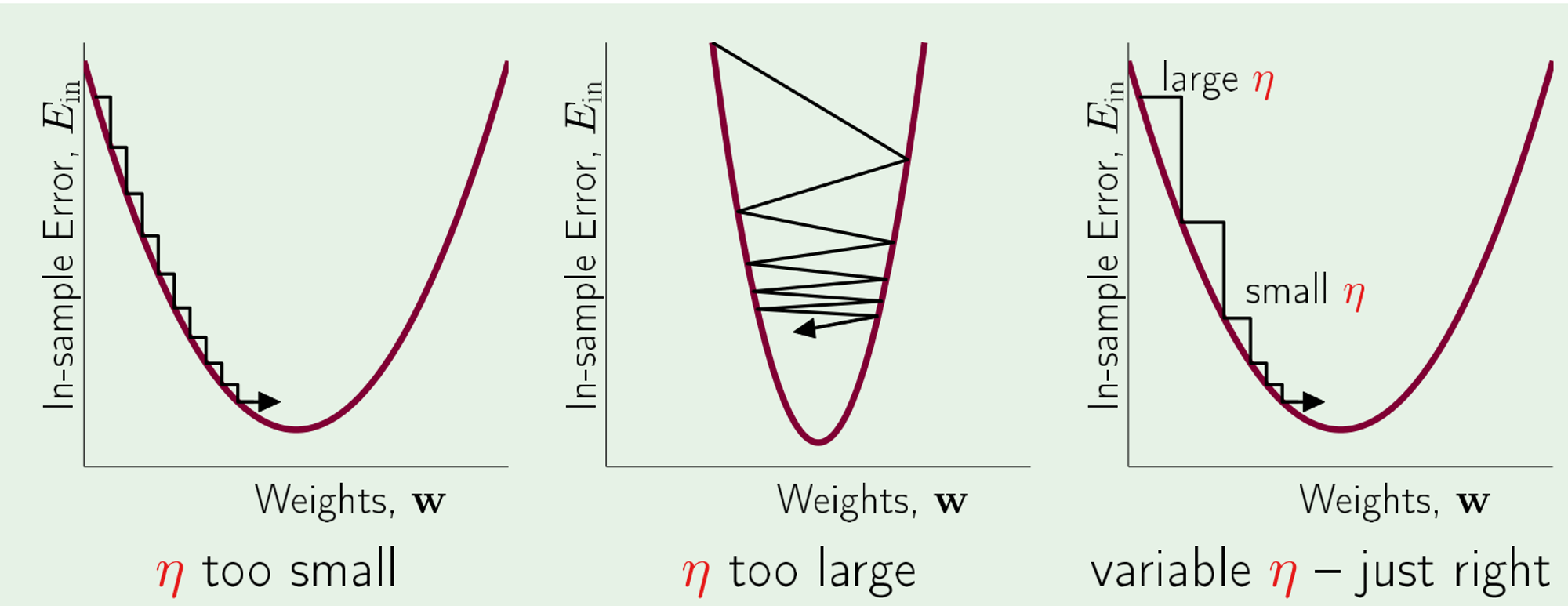
Large step size when far away from local minima
Small step size when close to the local minima
Simple Heuristic:
⇒ Learning rate algorithm
🥚 Stochastic Gradient Descent
Perform gradient descent for each batch, not the entire training set
- Randomly pick ONE training sample
- Compute the gradient of loss function w/ this sample
- Update the weights
🧺 Mini-Batch Gradient Descent
in between batch and stochastic
- Randomly pick training samples
- Compute the gradient of the loss associated with this mini-batch
- Update the weights
Comparing Gradient Descent Variants

🤔 Questions
- How gradient descent deals with local maxima / saddle points



