Created
Sep 7, 2021 06:02 PM
Topics
Why is the feasibility of learning questionable? Problem of LearningLearning TheoryThe Bin ExperimentHoeffding Inequality InterpretationConnection to LearningGeneralization to Multiple HypothesesSummaryTwo primary questions in learningComplexity of NotesIf Complexity of is too high: Overfitting OccursMeasuring Complexity of ML in PracticeTraining SetValidation SetTest SetAssumptionError Measures (Loss Functions)Other Error MeasuresIn PracticeExampleNoisy TargetsConclusion: Components of a Learning System
Feasibility of Learning
Previous Lecture Recap

Why is the feasibility of learning questionable?
Problem of Learning
Candidates functions converges on seen input & outputs
But diverges on unseen examples
Learning Theory
We cannot find a function that deterministically replicates
We can only give probability estimates:
- approximates with probability if unseen examples are drawn in the same way
The Bin Experiment
Given a bin of red & blue balls where and
- is unknown
Experiment: perform random sampling & record the sample proportion
- Let denote the fraction of red balls in sample of size
Hoeffding Inequality
Interpretation
- For large , probability that and being close to each other is high
- Tradeoff between sample size and closeness of approximation
- N ⇒ right ⇒ probability ⇒ closeness
- Not dependent on
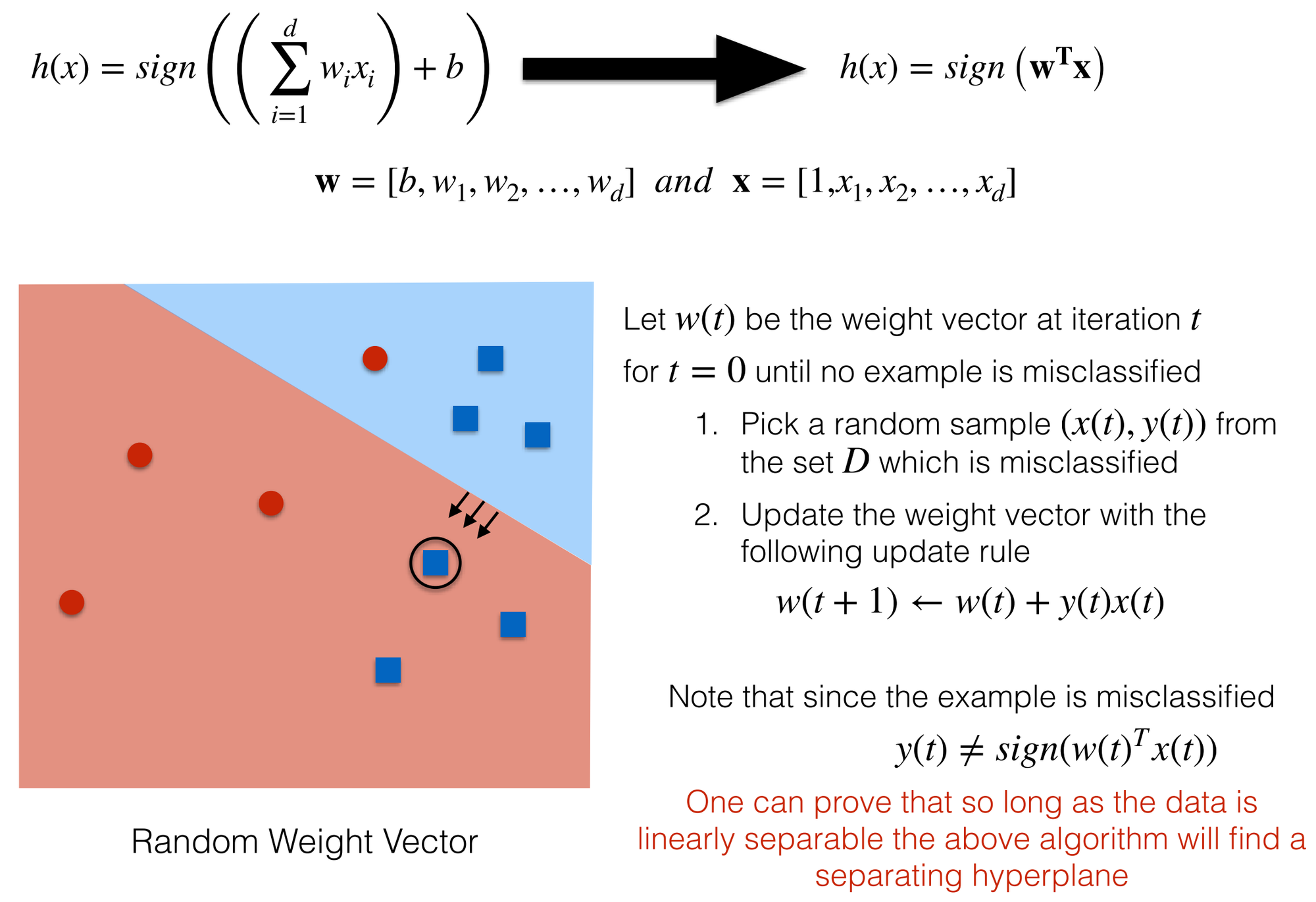
Connection to Learning
Consider some pre-selected hypothesis
Then for some fixed :
For a hypothesis fixed before looking at the data, the probability of the in-sample error deviating from out-of-sample error is low, if samples are independent using some probability distribution
- Single fixed hypothesis
- Hypothesis space
- Verification, not learning
- must be selected b4 seeing data
- Need to guarantee obtained after seeing data
Generalization to Multiple Hypotheses
Estimates for a function
The bound on the right-side is loose by
Summary
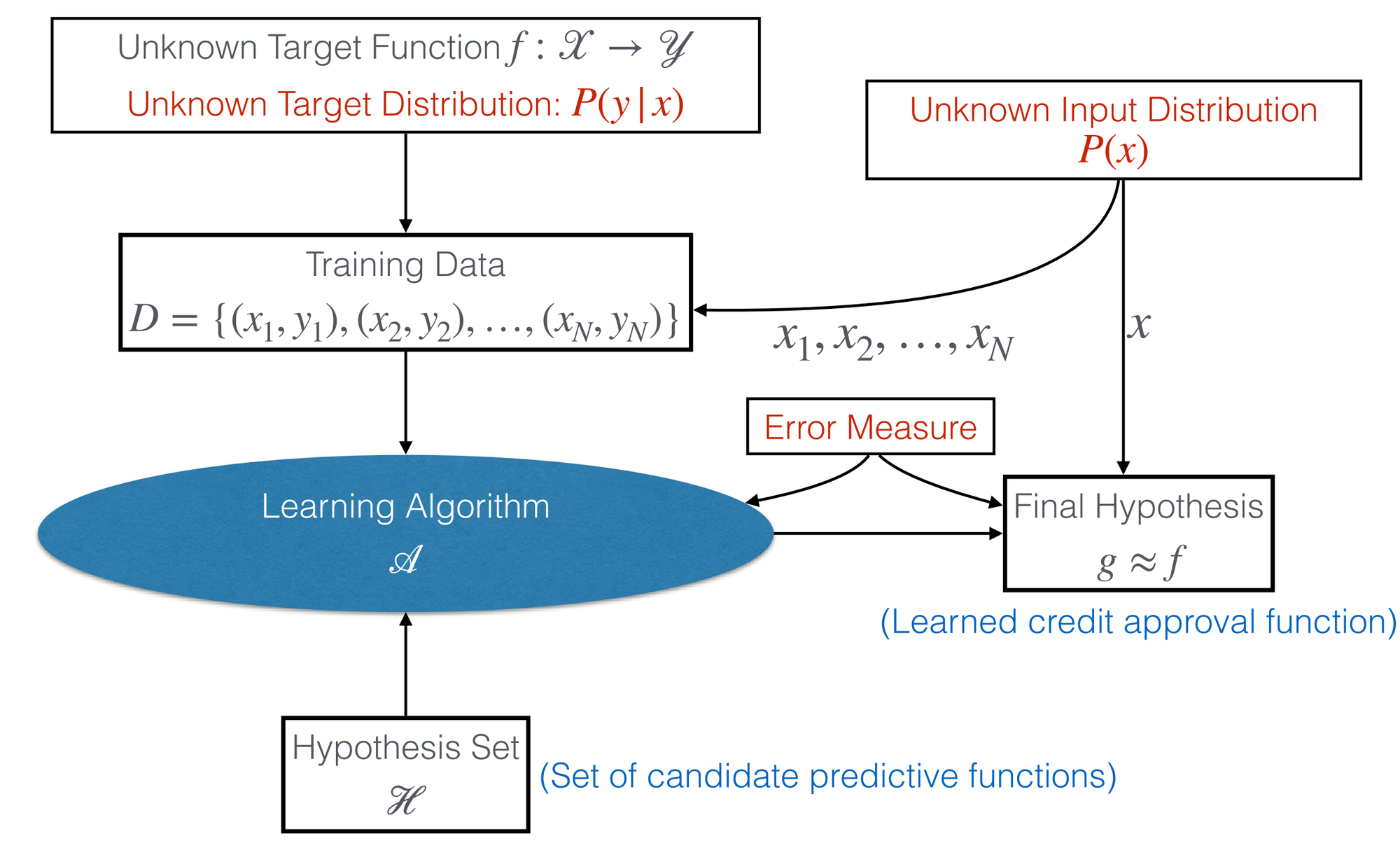
Goal: approximate the unknown function
Steps
- Provide a finite training set
- Assume each example independent
- Population has distribution
- Identify a hypothesis set to pick
- Bound the difference between in-sample and out-of-sample errors
- Assuming unseen samples are drawn with same distribution
- Hoeffding Inequality: if we can bring the in-sample error towards zero we can probabilistically guarantee that out-of-sample error will not be far either
- ⇒ will probabilistically approximate
Two primary questions in learning


Complexity of
= complexity of hypothesis space
Notes
Neural networks can approxiamate all functions
If complex enough & has enough data ⇒
If Complexity of is too high: Overfitting Occurs


Measuring Complexity of
VC Dimension (Not covered)
- Bias-Variance (Next Lecture Sep 9, 2021)
ML in Practice
Training Set
Use to tune the parameters of the model (search for the hypothesis)
Validation Set
Test the goodness of the running hypothesis
- Used to track the performance throughout learning
- Surrogate of the performance on unseen examples
- Information in this set is still being used to update the modal, though not used directly
Test Set
test data is used to measure the final performance of the model
- No going back after this
Assumption
Dataset is representative of the real world
Error Measures (Loss Functions)
Goodness of a model is measured by classification error
Other Error Measures
Binary classification error:
Squared error:
Cross-entropy loss:
In Practice
Defined by the user
Problem dependent
Decides which hypothesis gets selected at the end
Different error measures can lead to different hypothesis
Example

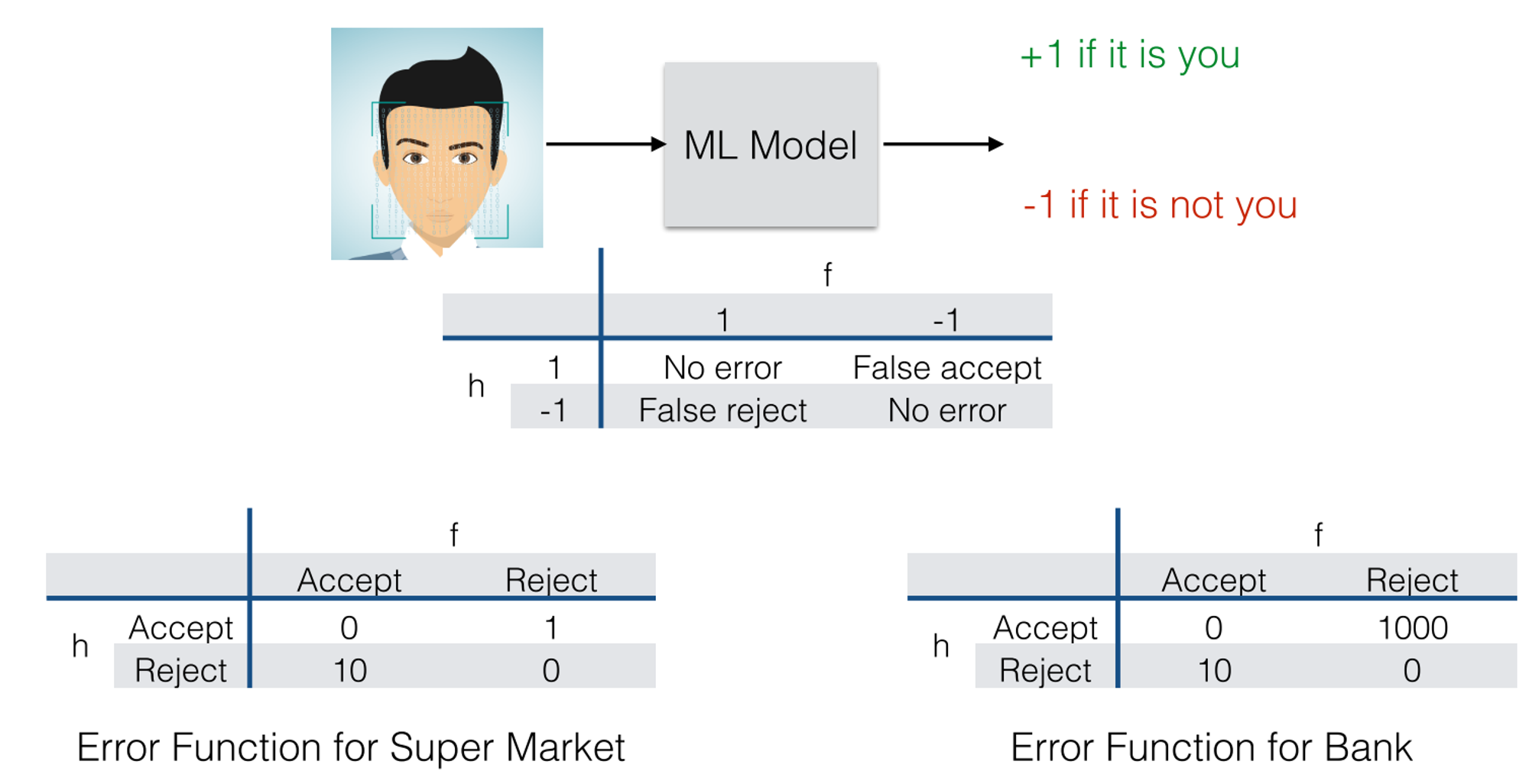
Notion: use the loss function to penalize the most costly mistakes
Noisy Targets
In reality, the mapping is rarely deterministic
- A data point is now generated by a joint distribution
- = Input Distribution: relative importance of the input samples
- = Target Distribution: interested in finding out
- Probabilistic, not deterministic