
Created
Dec 9, 2021 07:19 PM
Topics
CharacteristicsCompositionRewardReward Hypothesis of RLHistoryStateEnvironment State Agent State Information State (Markov State)EnvironmentFully Observable EnvironmentPartial Observable EnvironmentAgentPolicy Value Function ModelAlgorithmReinforcement LearningExploitation & ExplorationCurrent ProgressQuestionResources
Characteristics
- No supervisor, only reward signal
- Feedback is delayed, not instantaneous
- Time matters (sequential), non IID data
- Actions affect the subsequent data
Composition
Reward
- Scalar feedback signal
- Received after each step
Reward Hypothesis of RL
Maximization of expected cumulative reward = goals of the task
History
- Sequence of all observations, actions, rewards
- Except the current action
State
- A function of history
- Compresses the huge history sequence to a single vector
Environment State
Env's private state (not visible to agent)
From which generates next observation & reward
Agent State
Agent's internal representation
Any function of history
Inputs to the RL algorithm
Information State (Markov State)
Contains all useful info about the history
Markov Property
The future is independent of the past given the present
Question: 2 stage modeling?
- relates to
- But comes from
- does not relate to
Environment
Fully Observable Environment
- Agent directly observes env state
⇒ Markov Decision Process (MDP)
Partial Observable Environment
- Agent indirectly observes env state
- e.g. CV, trading bot, poker bot
⇒ Partially Observable Markov Decision Process (POMDP)
- Agent must construct own state representation
E.g.
Agent

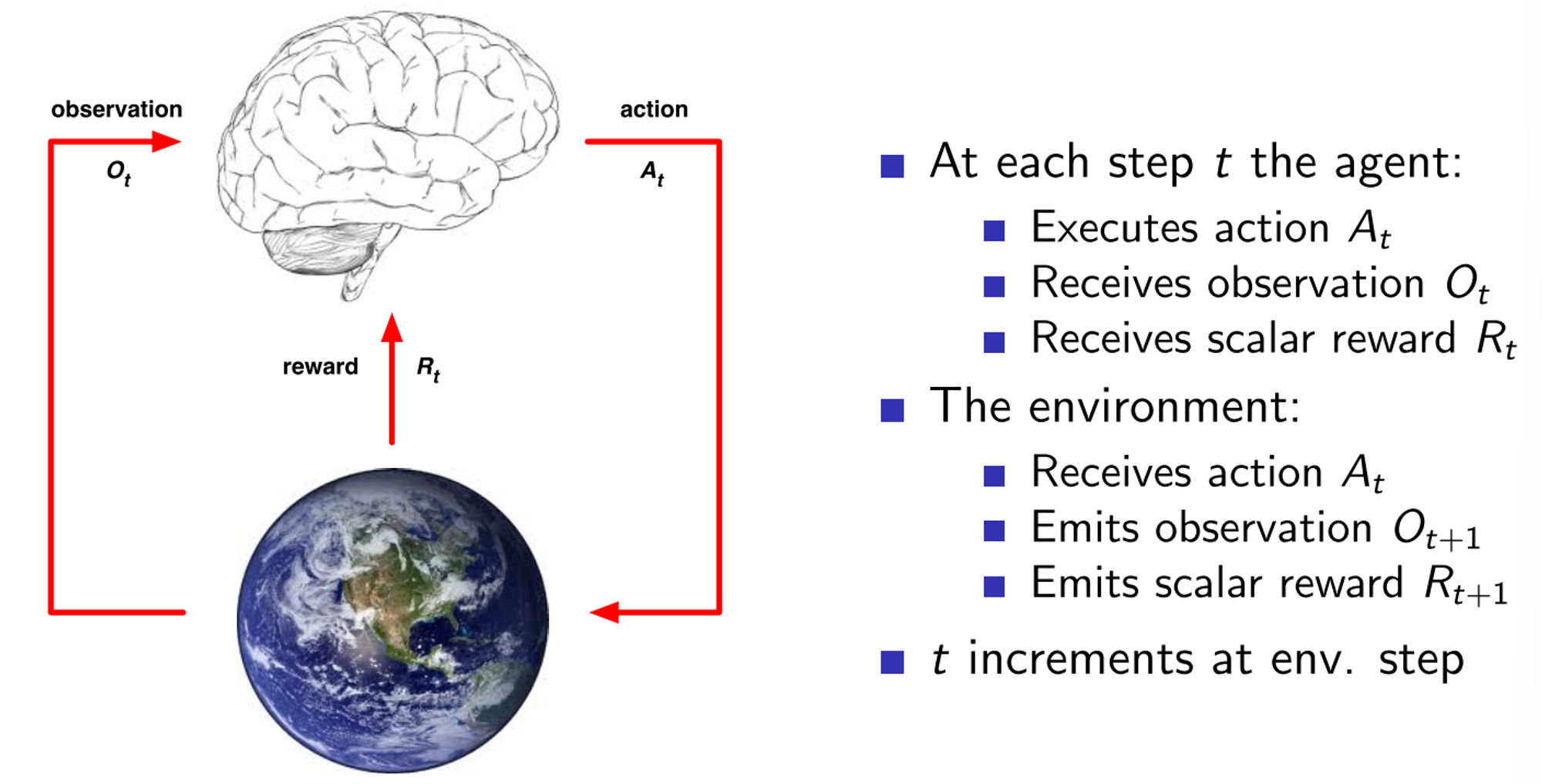
Policy
Defines the agent's behavior: maps state to action
- Deterministic policy:
- Stochastic policy:
Value Function
Predicts future reward by state
Evaluates goodness of states to choose an action
Model
Predicts immediate future state & reward by action
- Next State:
- Next Action:
Algorithm
Reinforcement Learning
Rules are unknown
Learn directly from interactive game play
Perform actions, see scores, make plans
Exploitation & Exploration
Exploitation: perform the best know action
Exploration: do something random
Current Progress
Value function is hard to learn
use DL to model the value function
Question
- Is RL a MPS or an alternative method?
- Can combine supervised learning & RL?
Resources



Jan 2, 2022

