
Created
Nov 16, 2021 07:10 PM
Topics
Dimensionally Reduction, PCA, Matrix Factorization
Unsupervised LearningTwo Learning ParadigmsDimensionality ReductionPurposeAssumptionExamplesCurse of dimensionalityWhy curse? When trying to fit data in 2DMethodsFeature ExtractionTypesLinear Feature TransformNon-Linear Feature TransformCriteriaPrincipal Component Analysis (PCA)IntuitionComputationDerivationEigenvalue magnitude % of varianceFinding one principle componentFull PCA algorithmHyper-parameter EstimationMethod: Singular Value Decomposition (SVD)Method: Eigen Decomposition (Diagonalization)Example Use CasesNon-negative Matrix Factorization (NMF)PurposeWhy no subtraction?Linear Discriminant Analysis (LDA)Loss FunctionGoalExampleFischer Discriminant AnalysisTermsLoss Function
Unsupervised Learning
Only inputs, no labels
Two Learning Paradigms
- Dimensionality reduction: feature selection
- PCA: linear
- Non-negative Matrix Factorization: linear
- Clustering: pattern detection
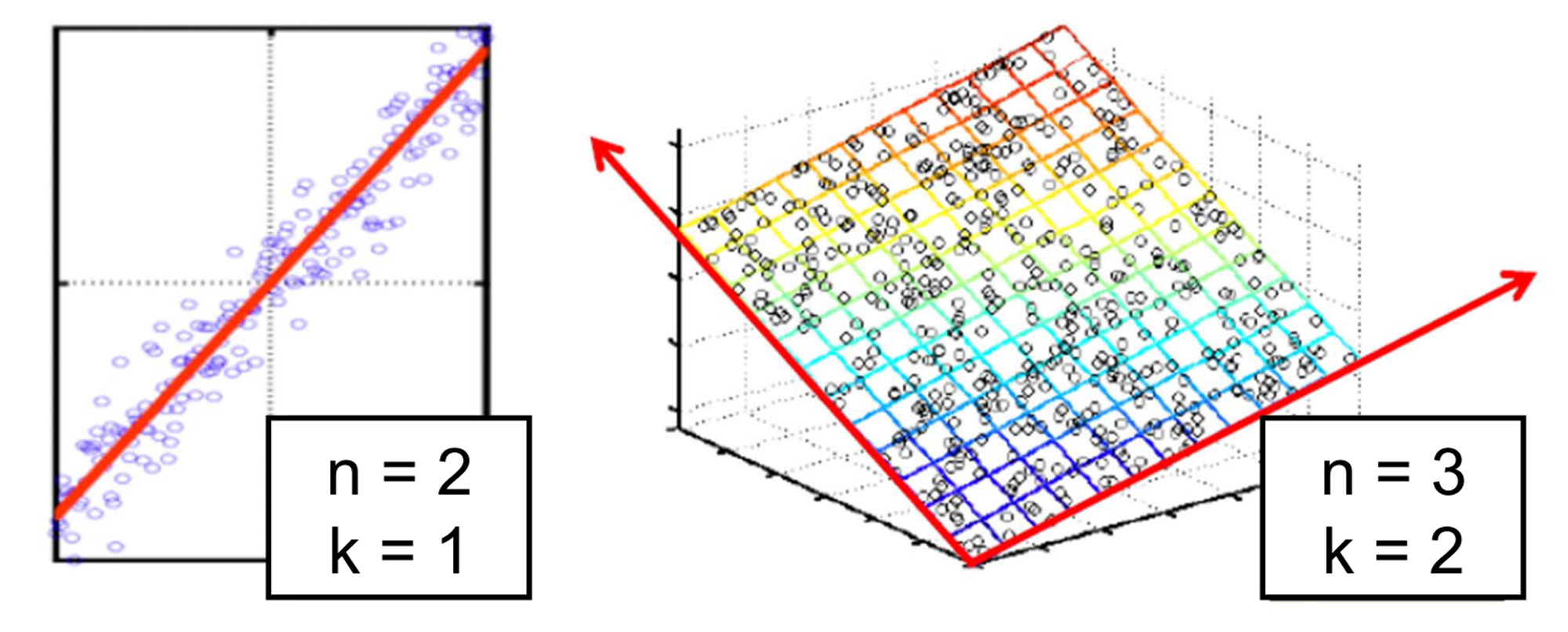
Dimensionality Reduction
Purpose
Computational: less space & time complexity
Statistical: better generalizability, less-prone to overfitting
Visualization: better human understandability
Anomaly detection: can detect outliers
Assumption
Data inherently lies in the low dimensional space
Examples
Source: 2; Intrinsic: 1
Source: 3; Intrinsic: 2

Hand-written Digits
Curse of dimensionality
Given a -dimensional sphere with volume
Volume of the outermost shell
As we increase dimension, most volume of the sphere in composed of the shell:
Why curse? When trying to fit data in 2D
- Granularity: maintain the # of bins in each axis
Keep density of bins constant: each bin has same number of samples
- Size of training set explodes: need more data
Keep the number of examples constant: same # as 1D
- Some bins becomes empty
Performance of classifiers degrade when dimensionality↑


- Need exponentially more data to fit a model in higher dimensions
Methods
- Feature Selection
- Feature Extraction
Feature Extraction


Types
Linear Feature Transform
- Principal Component Analysis (PCA)
- Non-Negative Matrix Factorization (NMF)
- Linear Discriminant Analysis (LDA)
- Local Linear Embedding (LLE)
- ISOMAP, etc.
Non-Linear Feature Transform
- Kernal PCA
- Auto-encoders, etc.
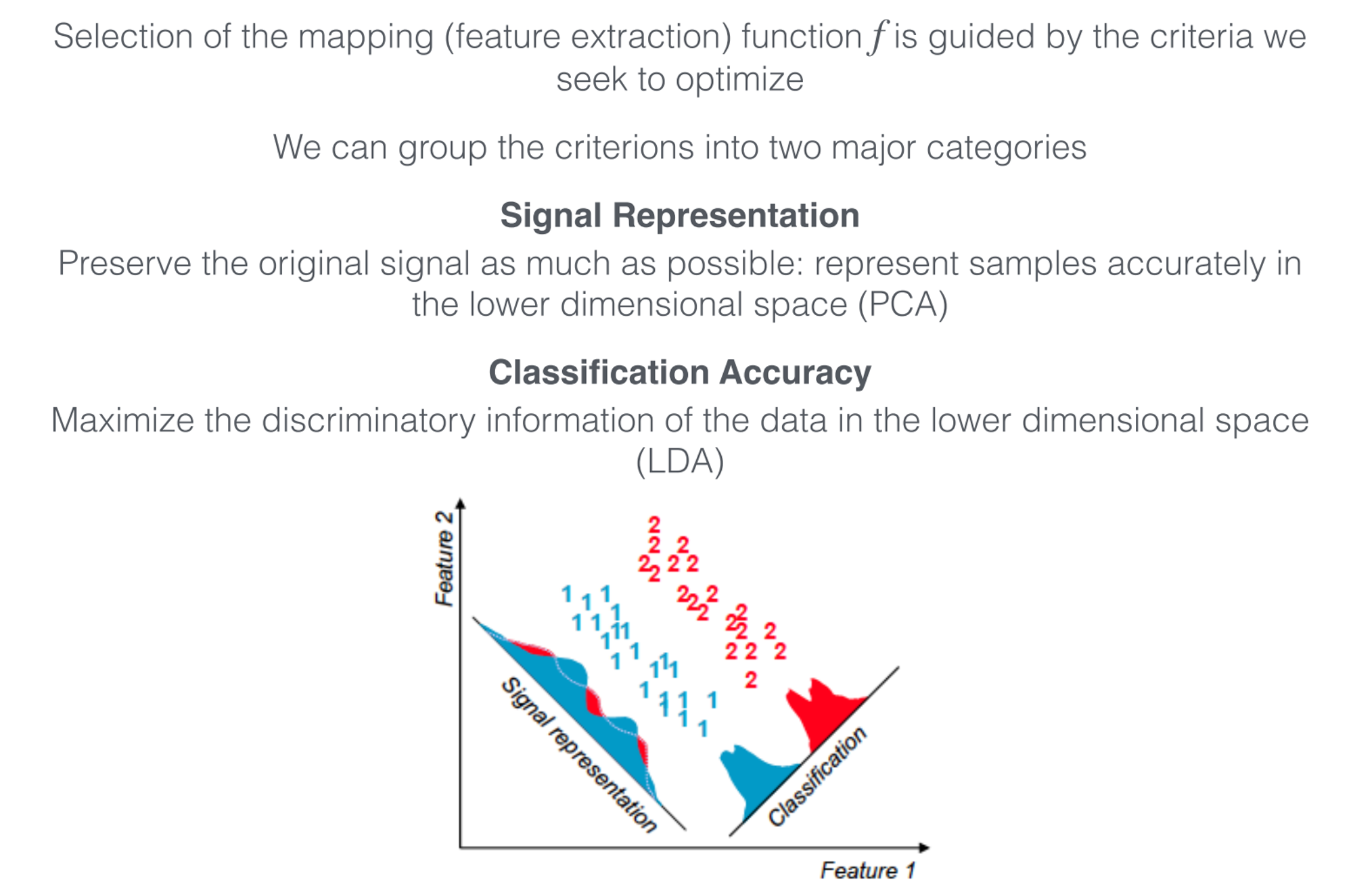
Criteria
Signal Representation
Classification Accuracy

Principal Component Analysis (PCA)
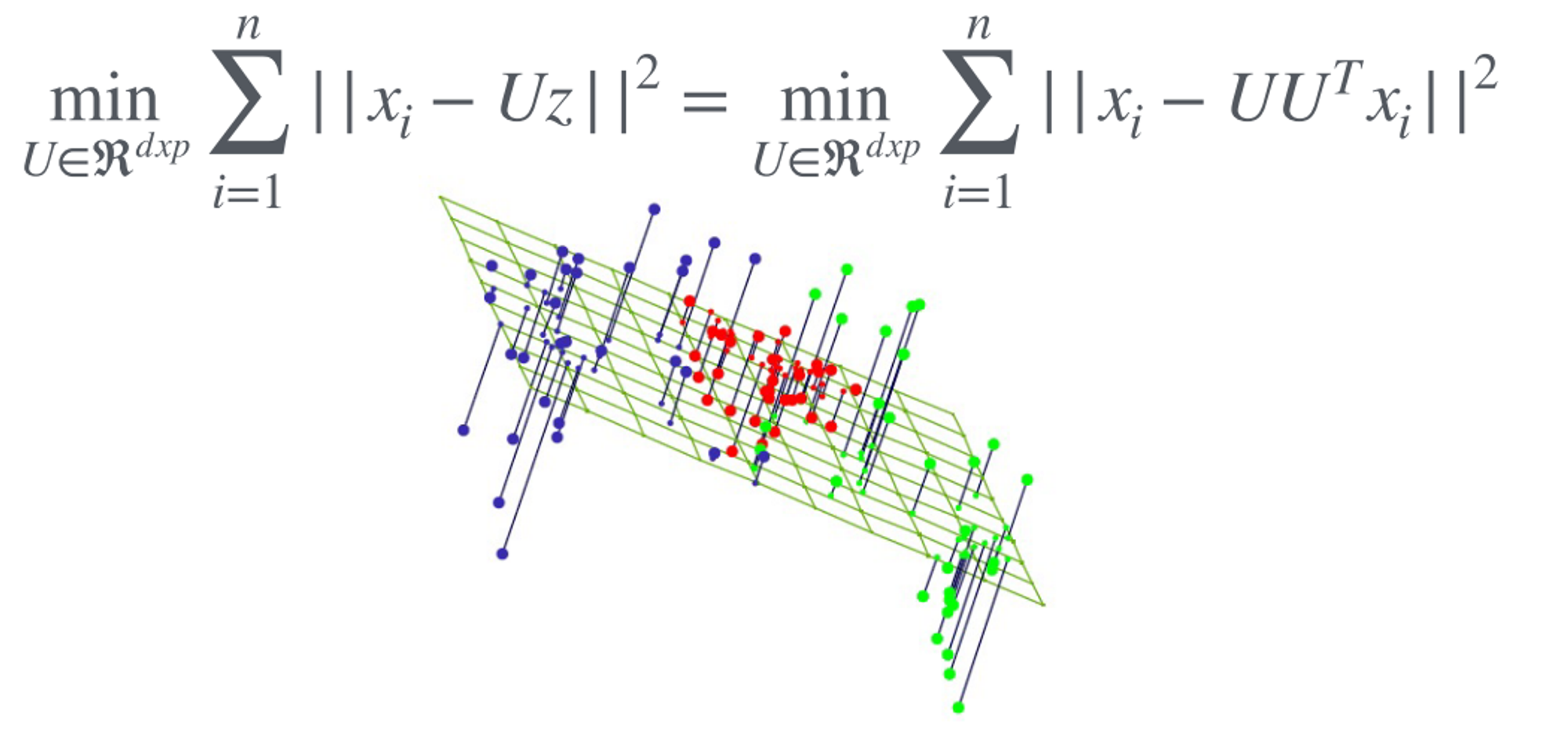
Intuition
Find a projection that can reconstruct the original input
- Project (Encode):
- Reconstruct (Decode):
- Minimize the reconstruction error

Equivalent to: Find a dimension with the highest variance


Computation
Derivation
Eigenvalue magnitude % of variance


Finding one principle component


Full PCA algorithm
- Recenter data: subtract mean from each column
- Compute Covariance Matrix
- Find Eigenvectors & Eigenvalues of
- The Eigenvectors w/ highest Eigenvalues = principal components
⚠️ Note: Computationally Inefficient
Hyper-parameter Estimation
By visual inspection:
- Eigenvalues drop after some value
- Ignore the dimensions w/ small Eigenvalues
Method: Singular Value Decomposition (SVD)
A practical way of performing PCA
- Compute SVD of input data matrix :
- Left singular vectors principal components of
Time Complexity:
Method: Eigen Decomposition (Diagonalization)
- Compute eigen decomposition of covariance matrix
Example Use Cases
Eigen Faces


Latent semantic analysis
Non-negative Matrix Factorization (NMF)
PCA w/ a non-negative constraint on
- Projection matrix
- Dim-reduced input
Purpose
PCA: ⇒ adding / subtracting elements
NMF: is created only by summing elements of the dictionary
⇒ Reduced input becomes more interpretable
Why no subtraction?
E.g. subtracting noses from lips does not make any sense
This assumption is particular to input data type
- NMF is NOT universally better than PCA
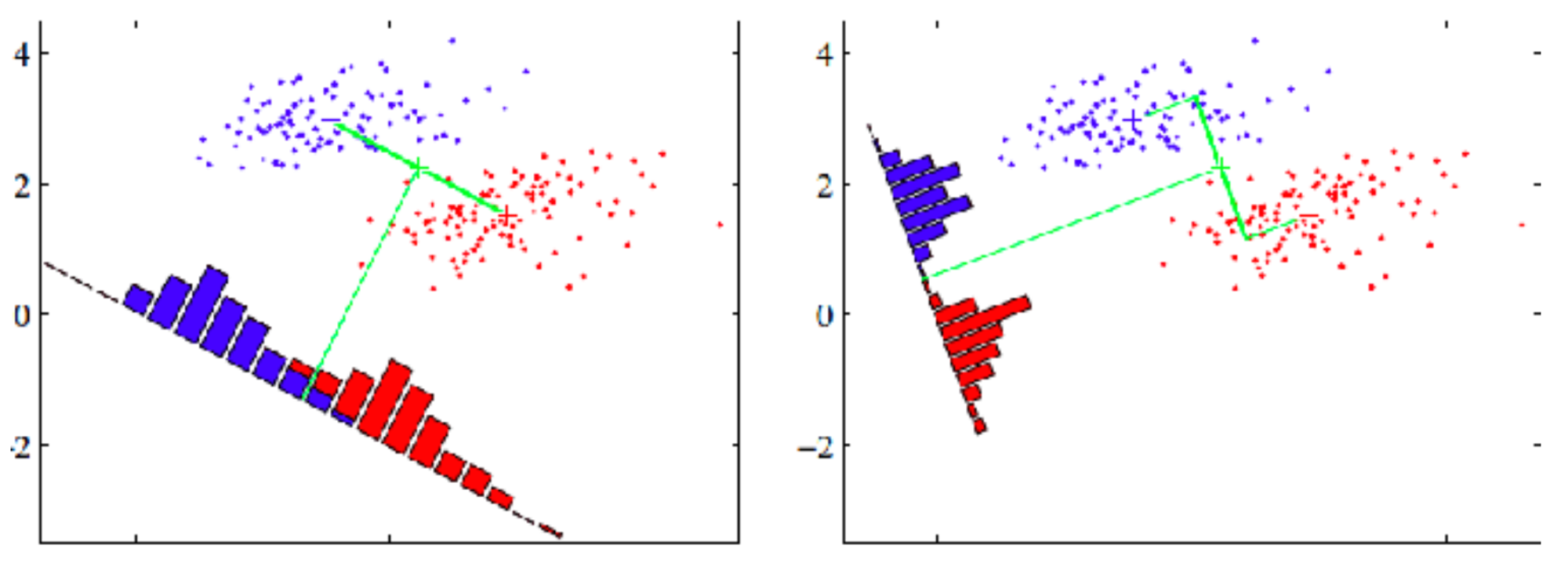
Linear Discriminant Analysis (LDA)
Dimensionality reduction w/ labels
Find a direction of projection that maximizes separation
: mean of input samples in class (dimensional )
: mean of projected samples in class (dimensional )
Loss Function
Goal
Maximize distance between projected means
Example
Bad: small gap
Good Direction: big gap

❓In linear algebra terms:
argmax the direction of eigenvector Fischer Discriminant Analysis
Increase distance between class means
+ Decease variance within classes
= LDA normalized by within-class scatter
Terms
- Scatter of a class:
- Within-class scatter : variance of points in a class

