
Created
Nov 9, 2021 07:18 PM
Topics
Bagging & Boosting
Bagging (Bootstrap Aggregating)Bootstrap SamplingClassification Tree ExampleSetup & TrainingMaking PredictionsOut-of-Bag (OOB) Error EstimationRandom ForestsRandom Feature SelectionSummaryAnalysisBoostingPredictionIntuitionAdaboostGradient BoostingIntuitionProcedureTheory: Relation to GradientsUpdate RuleGradient Boosted Decision Trees (if time permits)
Bagging (Bootstrap Aggregating)
Reduce variance w/o increasing bias
: Averaging reduce variance
E.g. Cross Validation: give more stable error estimate by averaging multiple independent folds
Bootstrap Sampling
A method to sample from our sample data to simulate sampling from the population
- Use empirical distribution of our data to estimate the true unknown data-generating distribution
- Not all samples will be chosen and each could be chosen twice
- P(chosen) = 0.632
Classification Tree Example
Average the predictions over a collection of bootstrap samples
Setup & Training
Number of trees =
Bootstrap sample size = original sample size
Train each tree on each bootstrap sample
Making Predictions
- Plurality vote over the predictions
- Predict with the combined probabilities
- More well behaved than 1.
Out-of-Bag (OOB) Error Estimation
OOB Samples: remaining sample not contained in each bootstrap samples
⇒ See as test data
- Each sample is an OOB for trees
- Predict the response for the i-th observation
? When to record if a sample is OOB
Random Forests
Decorrelates individual bagged trees by small tweaks
Random Feature Selection
Essentially drop out a random subset of input features
At each node, select a random subset of predictors
Split along the best in the subset
In practice:
Summary


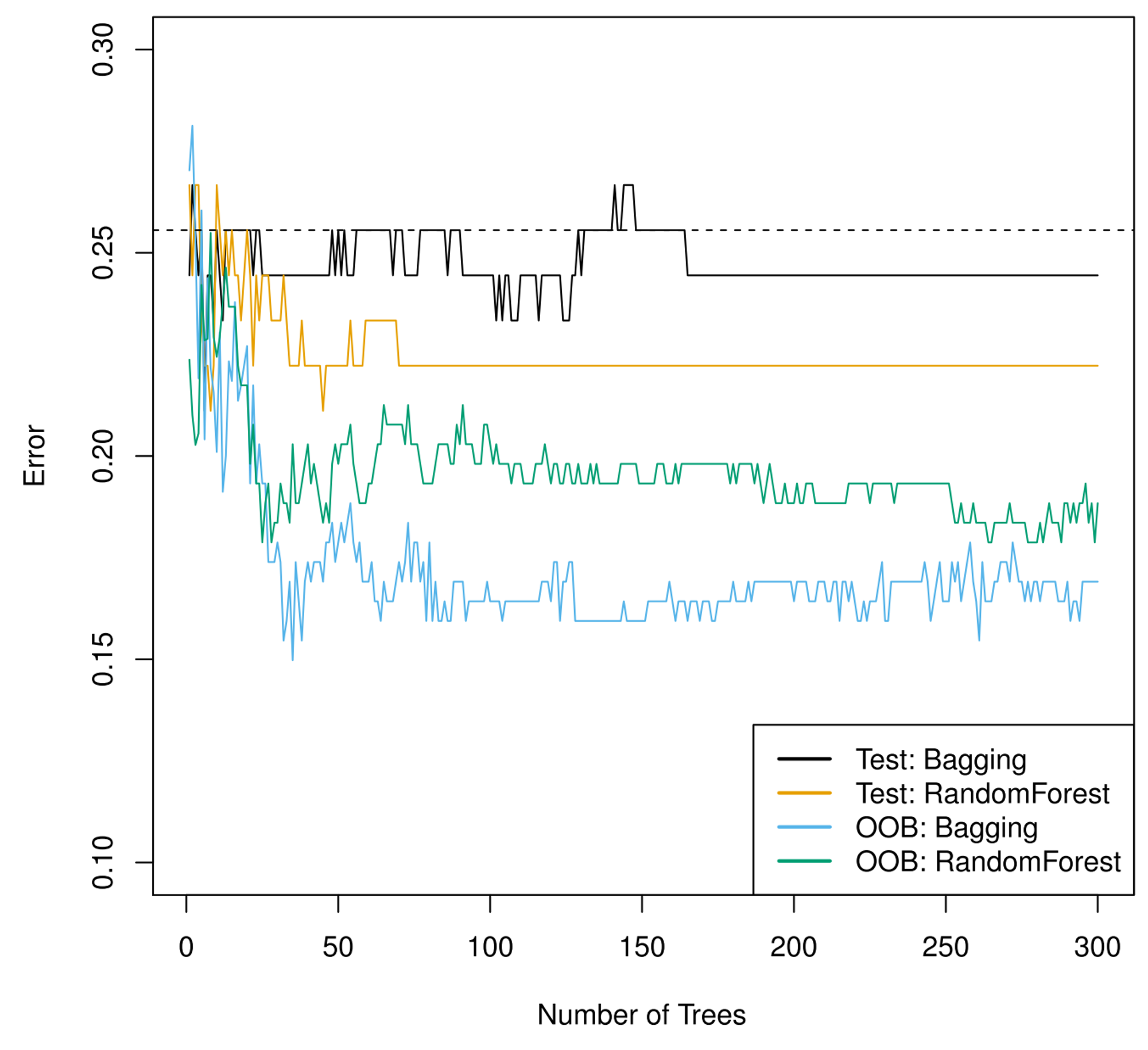
Analysis
Random forests are better predictors than bagged trees

Boosting
A sequential (iterative) process:
Combine multiple week classifier to classify non-linearly-separable data
Weak learner: a classification model w/ accuracy little more than 50%
- If use a strong learner, will 100% overfit
- Associate a weight to each training sample:
- Loop until convergence:
- Train the weak learner on a bootstrap sample of the weighted training set
- Increase for misclassified sample ; decrease otherwise
Prediction
DO a weighted majority voting on trained classifiers
Intuition

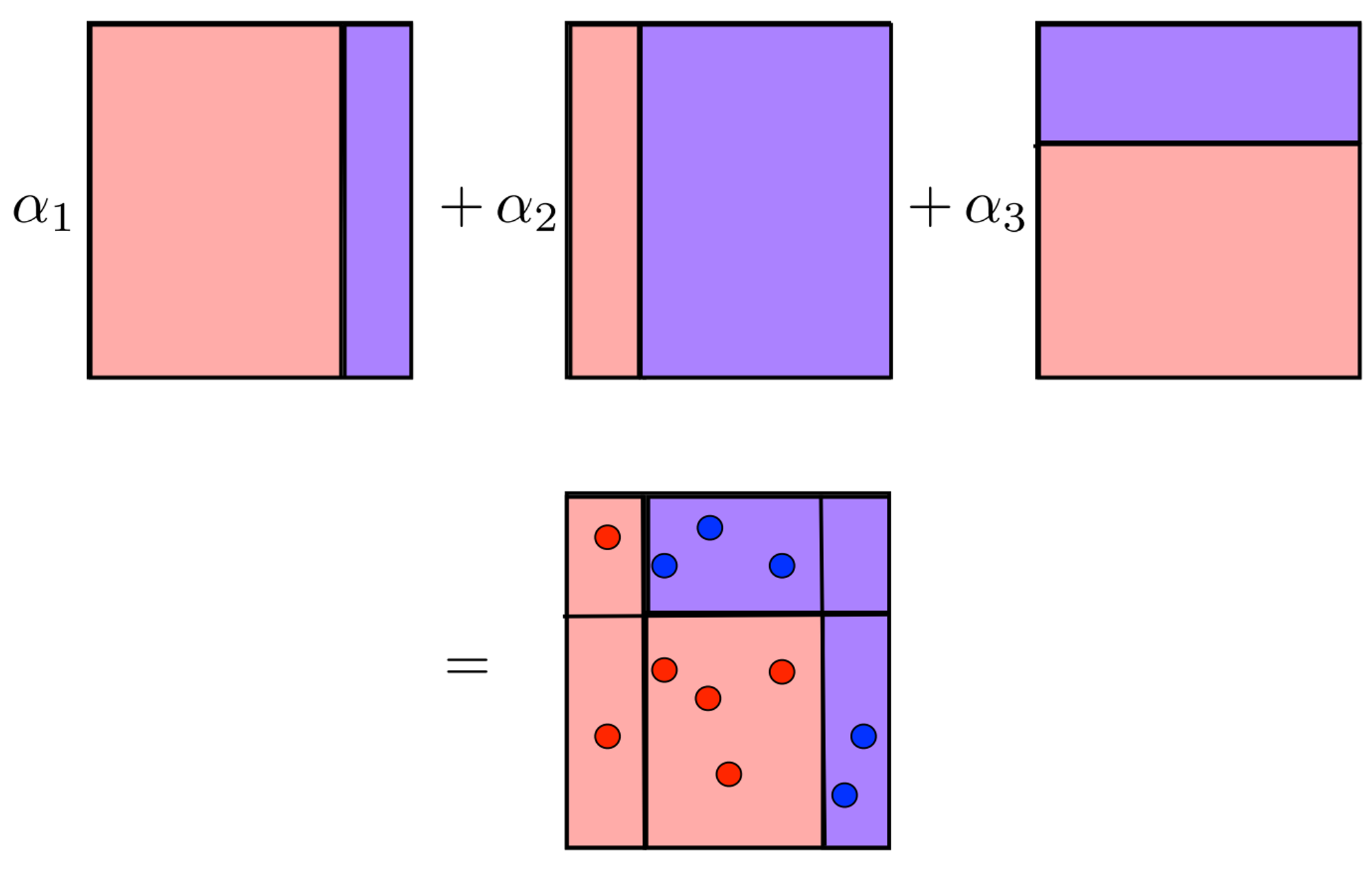
Adaboost


- = weight for model
- = classification error for model
- weight of sample computed from model 's classification errors
Gradient Boosting
Fit a model on the residuals & add it to the origional
Intuition
Given a model non-perfect model F
- Cannot delete anything from model F
- Can only add additional model to F to get
by intuition
Use regression to find
Procedure
Training set = residuals of the model
Train on
New Model =
Repeat until satisified
Theory: Relation to Gradients
Squared Loss function
Minimize wrt gives
⇒ Residuals gradients
Update Rule
Can use other loss function

